- 1 ¿Qué es la ciencia de datos?
- 2 Una presentación a toda marcha de R
- 3 Poniendo los datos en forma
- 4 Visualización
- 5 Modelado estadístico
- 6 Información geográfica y mapas
4.5 Histogramas
Los histogramas son usados para mostrar la distribución de una variable continua. El histograma permite decir si los valores que toma cada observación se agrupan en torno a un valor “típico” o medio -como en el caso de la llamada distribución normal-, o en torno a dos valores frecuentes (distribución bimodal), o con dispersión sin picos ni valles, donde no hay valores típicos ni atípicos - distribución uniforme.
Por ejemplo, analicemos la distribución de registros mensuales (la columna PERIODO en nuestro dataset representa el lapso de un mes). Tenemos que agrupar por mes, y hacer un resumen (summarise()) que extraiga el gran total:
contactos_por_mes <- atencion_ciudadano %>%
group_by(PERIODO) %>%
summarise(gran_total = sum(total))
head(contactos_por_mes)## # A tibble: 6 × 2
## PERIODO gran_total
## <int> <int>
## 1 201301 43826
## 2 201302 43666
## 3 201303 47405
## 4 201304 50768
## 5 201305 52761
## 6 201306 48344Hacer un histograma es simple con geom_histogram(): sólo hay que elegir una variable y asignarla a las x.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.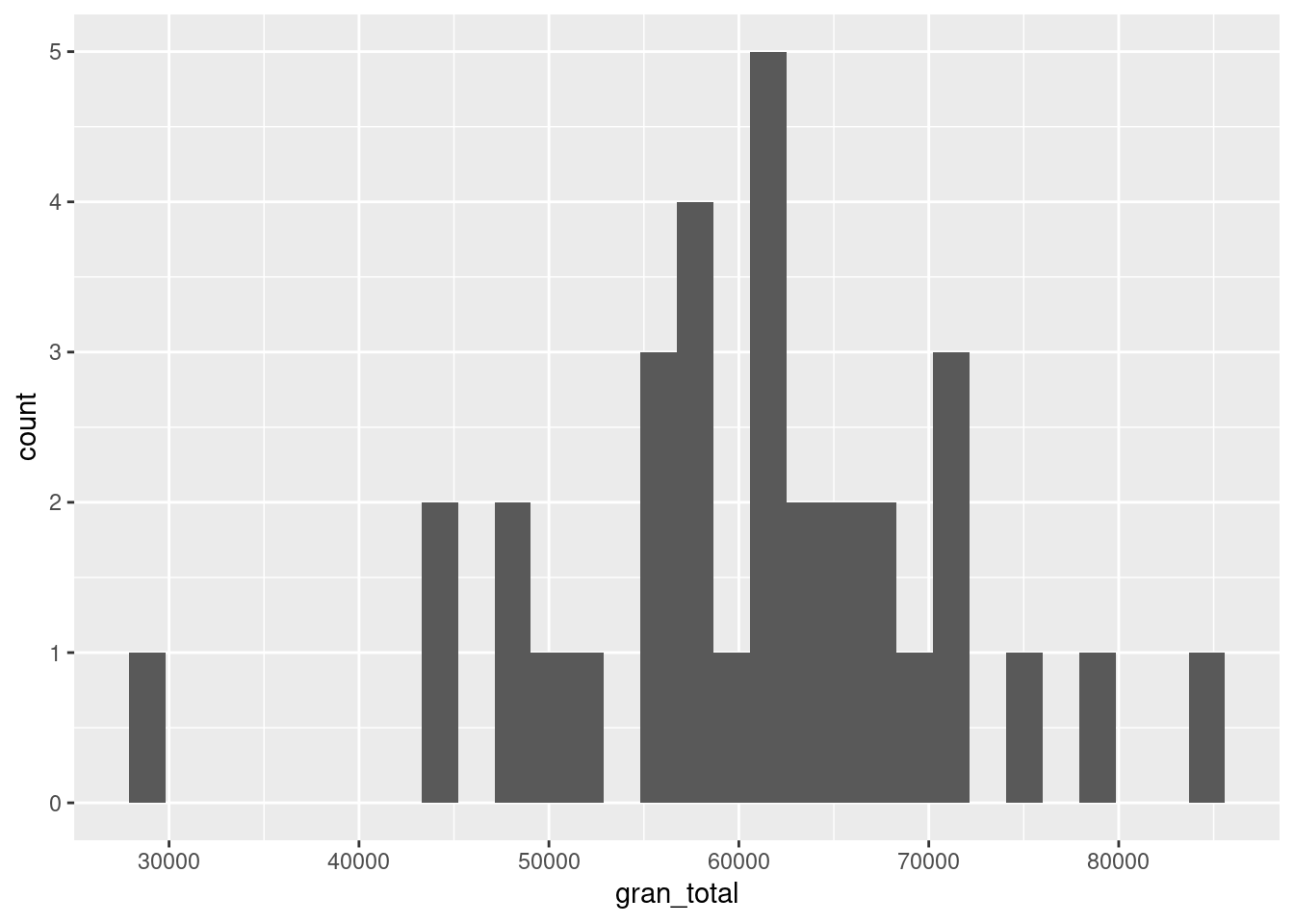
geom_histogram() divide el rango de valores en una cantidad arbitraria de segmentos iguales (“bins” en inglés) y cuenta cuantas observaciones caen en cada uno, cantidad que se representa con la altura de la columna en el eje de las y.
En nuestro ejemplo, vemos que un mes mes en el que la cantidad de registros tiende a agruparse en torno a un valor típico de poco más de 60.000 por mes. En apenas un caso hubo menos de 40.000 o más de 80.000
No sería raro que la agregación que hicimos nos oculte patrones en los datos. Que pasa si contamos los registros por mes y por tipo de contacto, y mostramos los histogramas mensuales en facetado por tipo?
Hacemos el agrupado y sumario de rigor
contactos_por_mes_y_tipo <- atencion_ciudadano %>%
group_by(PERIODO, TIPO_PRESTACION) %>%
summarise(gran_total = sum(total))## `summarise()` has grouped output by 'PERIODO'. You can override using the `.groups` argument.## # A tibble: 6 × 3
## # Groups: PERIODO [2]
## PERIODO TIPO_PRESTACION gran_total
## <int> <chr> <int>
## 1 201301 DENUNCIA 2740
## 2 201301 QUEJA 889
## 3 201301 RECLAMO 16011
## 4 201301 SOLICITUD 15325
## 5 201301 TRAMITE 8861
## 6 201302 DENUNCIA 2463y creamos el facetado como ya sabemos:
ggplot(contactos_por_mes_y_tipo) +
geom_histogram(aes(x = gran_total)) +
facet_wrap(~TIPO_PRESTACION)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.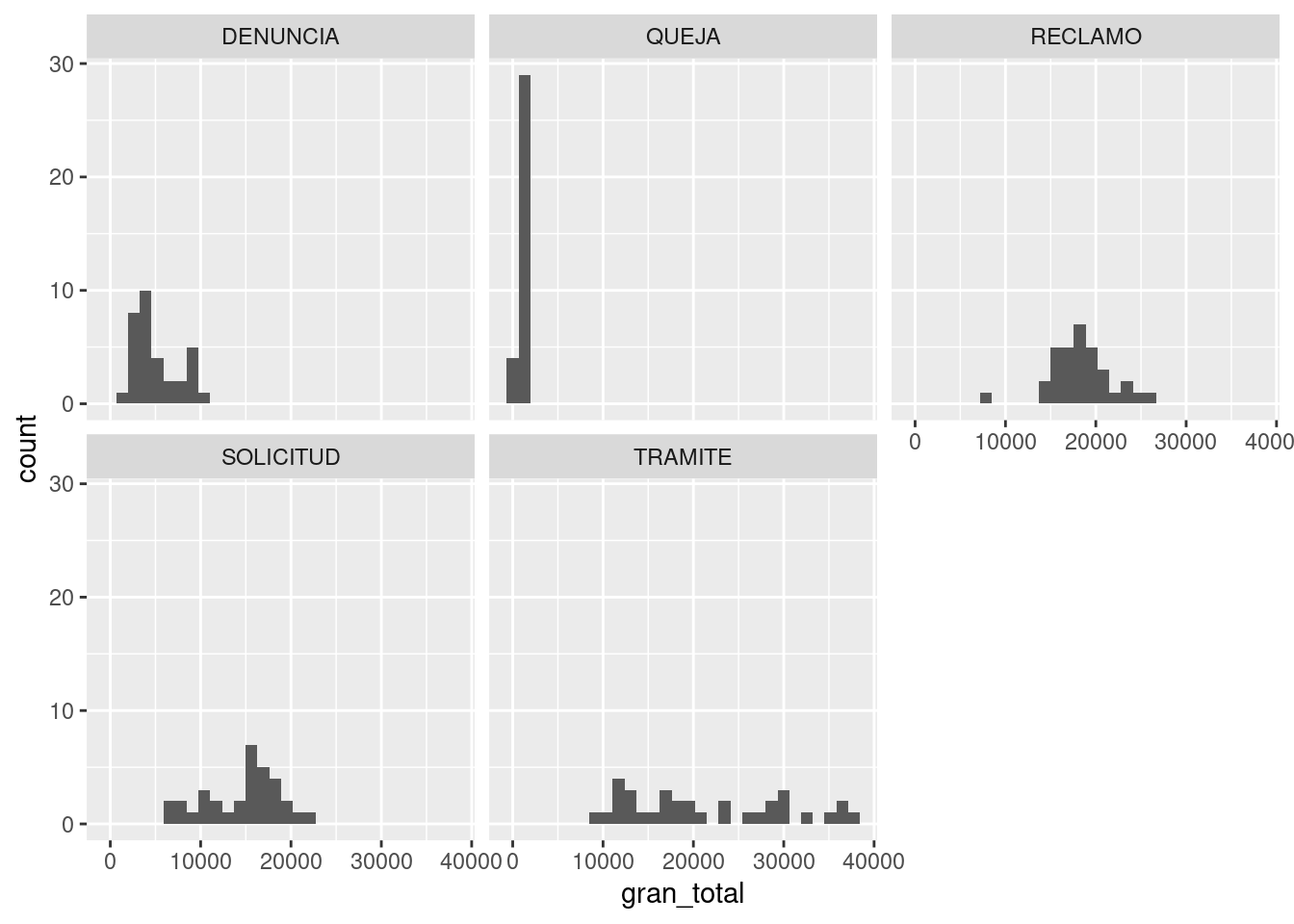
Aparecen las diferencias. Los reclamos tienen una dispersión mínima, con casi todas las observaciones apiladas en torno a unos 1000 contactos mensuales; siempre son bajas. La cantidad mensual de denuncias, reclamos y solicitudes muestra una dispersión mayor, pero aún así tendencia a rondar un valor típico. Los trámites son el extremo opuesto a las quejas, ya que muestran una gran dispersión, pudiendo tomar cualquier valor de menos de 10.000 a más de 40.000 registros de forma bastante pareja.