- 1 ¿Qué es la ciencia de datos?
- 2 Una presentación a toda marcha de R
- 3 Poniendo los datos en forma
- 4 Visualización
- 5 Modelado estadístico
- 6 Información geográfica y mapas
4.3 Facetado
Ya sabemos como representar variables usando atributos estéticos. Con esa técnica podemos mostrar con claridad dos o tres variables en un plano bidimensional (nuestro gráfico). Pero cuando si queremos agregar más atributos para codificar variables adicionales, la visualización pierde legibilidad de inmediato. Por suerte existe otra técnica, que podemos usar en combinación con la estética, para agregar aún más variables: el facetado.
Las facetas son múltiples gráficos contiguos, con cada uno mostrando un subconjunto de los datos. Son útiles sobre todo para variables categóricas.
Practiquemos con un ejemplo. Sabemos que en la comuna 1 se registra una cantidad de contactos de la ciudadanía mucho mayor que en las demás. ¿La diferencia será igual para todas las categorías de contacto, o existe alguna en particular que es la que inclina la balanza?
En nuestro dataframe original, el tipo de contacto aparece en la columna “TIPO_PRESTACION”. El nombre que eligieron no es del todo informativo, pero summary() (recuerden siempre lo usamos para explorar un dataset que no conocemos) nos da una pista:
## PERIODO RUBRO TIPO_PRESTACION BARRIO total COMUNA
## Min. :201301 Length:57431 Length:57431 Length:57431 Min. : 1.00 Min. : 1.000
## 1st Qu.:201309 Class :character Class :character Class :character 1st Qu.: 1.00 1st Qu.: 4.000
## Median :201404 Mode :character Mode :character Mode :character Median : 4.00 Median : 9.000
## Mean :201401 Mean : 34.85 Mean : 8.119
## 3rd Qu.:201503 3rd Qu.: 16.00 3rd Qu.:12.000
## Max. :201512 Max. :19221.00 Max. :15.000
## NA's :63
## AÑO MES
## Length:57431 Length:57431
## Class :character Class :character
## Mode :character Mode :character
##
##
##
## “TIPO_PRESTACION” es la categoría más general, con sólo cinco niveles - “DENUNCIA”, “QUEJA”, “RECLAMO”, “SOLICITUD” y “TRAMITE”. Las otras variables categóricas, asumimos, representan subtipos.
Agrupamos entonces nuestra data por comuna y por tipo de contacto, sin olvidar agregar luego los datos de población
contactos_por_comuna_y_tipo <- atencion_ciudadano %>%
group_by(COMUNA, TIPO_PRESTACION) %>%
summarise(miles_contactos = sum(total) / 1000 ) %>%
left_join(habitantes)## `summarise()` has grouped output by 'COMUNA'. You can override using the `.groups` argument.## Joining, by = "COMUNA"## # A tibble: 6 × 4
## # Groups: COMUNA [2]
## COMUNA TIPO_PRESTACION miles_contactos POBLACION
## <int> <chr> <dbl> <int>
## 1 1 DENUNCIA 22.9 253271
## 2 1 QUEJA 17.4 253271
## 3 1 RECLAMO 55.7 253271
## 4 1 SOLICITUD 20.9 253271
## 5 1 TRAMITE 568. 253271
## 6 2 DENUNCIA 10.2 149720Listos para facetar. Producimos un scatterplot igual que antes, y le agregamos una capa adicional con facet_wrap(). La variable a “facetar”, la que recibirá un gráfico por cada una de sus categorías, siempre se escribe a continuación del signo ~; en nuestro caso, queda como ~TIPO_PRESTACION. El simbolillo en cuestión denota lo que en R se denomina una fórmula y ya nos lo cruzaremos de nuevo, pero por ahora no le prestamos más atención.
ggplot(contactos_por_comuna_y_tipo) +
geom_point(aes(x = POBLACION, y = miles_contactos)) +
facet_wrap(~TIPO_PRESTACION)## Warning: Removed 5 rows containing missing values (geom_point).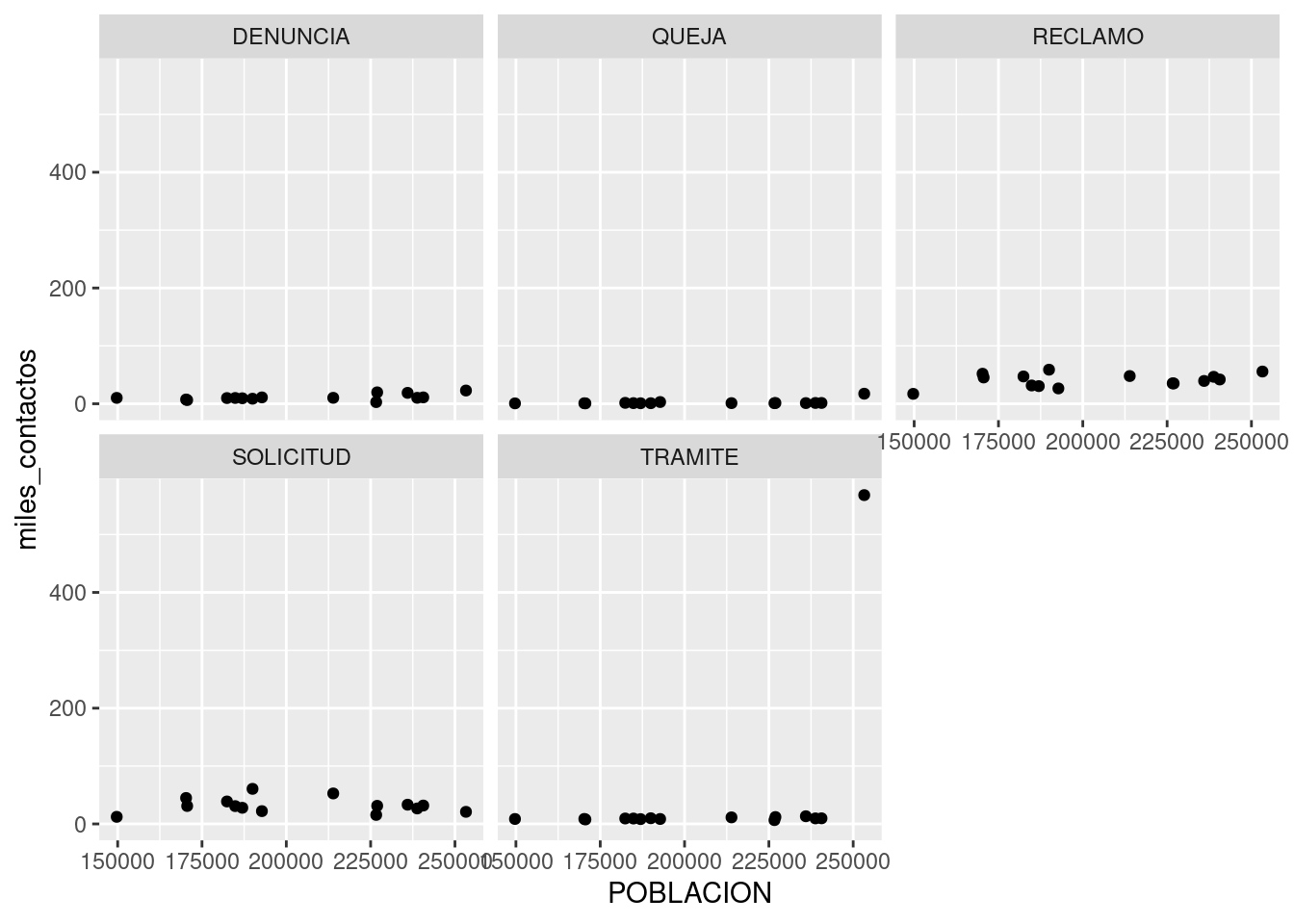
Los culpables de la anomalía son los trámites; en ninguna otra categoría la comuna 1 se separa del resto. Sabiendo que la base de donde provienen los datos combina información de distintos sistemas de atención, mi interpretación es que una gran cantidad de “TRAMITES” proviene de algún sistema administrativo que no guarda direcciones. Si ese fuera el caso, parece que a todos los trámites huérfanos de origen se les asigna una dirección en la Comuna 1 (sede histórica del Gobierno de la Ciudad) y nosotros terminamos haciendo estas elucubraciones.
Pero valga el ejemplo para mencionar algo fundamental: por más ciencia de datos que apliquemos, siempre vamos a llegar a un punto en que nuestros hallazgos no tendrán sentido sin combinarlos con lo que se llama “conocimiento de dominio”. El conocimiento de dominio es el saber especializado sobre el tema que estamos tratando, sea el ciclo reproductivo de la gaviota austral o la organización administrativa del Gobierno de la Ciudad Autónoma de Buenos Aires. Esto no debería desanimarnos, ¡al contrario!. El análisis de datos como profesión conlleva un constante aprendizaje sobre los más variados temas. Y a la inversa: si somos expertos en cualquier campo, aún con un puñado de técnicas básicas de R podemos extraer conocimiento de nuestros datos que jamas encontraría un experto programador que no conoce el paño.