- 1 ¿Qué es la ciencia de datos?
- 2 Una presentación a toda marcha de R
- 3 Poniendo los datos en forma
- 4 Visualización
- 5 Modelado estadístico
- 6 Información geográfica y mapas
2.1 Nuestro primer proyecto en R
A continuación reproduciremos un ejercicio paso a paso, para ilustrar la potencia de una herramienta de análisis como R. Que nadie se preocupe si algunas de las operaciones parecen no tener sentido, o resultan arbitrarias. ¡Es normal! Nadie aprende un lenguaje en 10 minutos, sea R o esperanto. La idea es tener exposición temprana a un caso de uso interesante, usando datos reales. Y que nos sirva como motivación para practicar luego ejercicios básicos que son muy necesarios pero, a veces, no tan emocionantes.
2.1.1 A investigar: ¿Cual es la diferencia en mortalidad infantil entre el sur y el norte de la Ciudad Autónoma de Buenos Aires?
Buenos Aires es una ciudad que desde hace décadas presenta una marcada polarización entre sus barrios del sur, relativamente menos desarrollados, y los del norte donde el nivel socioeconómico y la calidad de vida son mayores.
Figura 2.1: Artículo en la edición online de El País
Uno de los aspectos más lamentables de la disparidad norte-sur, y sin duda de los que más polémica y acusaciones cruzadas ha generado, es la diferencia en la tasa de mortalidad infantil de acuerdo a la región de la ciudad.
¿Qué tan grande es esa diferencia? ¿Cómo se distribuye geográficamente?
Vamos a utilizar R para responder esas preguntas y visualizar los resultados de nuestro análisis, utilizando como fuente cifras oficiales publicada por la ciudad.
2.1.2 Crear un proyecto en RStudio
El primer paso es ejecutar RStudio, que ya deberíamos tener disponible en nuestro sistema.
Una vez abierta la interfaz gráfica, creamos un proyecto nuevo, cliqueando en File -> New Project... -> New Directory -> New Project. En la ventana que surge, elegir un nombre para el proyecto (por ejemplo, “Practicando R”) y finalizar la operación cliqueando en Create project.
Utilizar proyectos nos permite continuar otro día desde donde dejamos la tarea al terminar una sesión. Es sólo cuestión de recuperar el proyecto deseado la próxima vez que abrimos RStudio, cliqueando en File -> Recent Projects -> "nombre de mi proyecto".
Por ahora, sigamos trabajando. Vamos a crear un “script”. Un script, como su nombre en inglés lo indica, es un guión; una serie de pasos que escribimos para que nuestra computadora ejecute en secuencia. Cliqueamos en File -> New File -> R Script. De inmediato se abre una ventana con un editor de texto. ¡Ahora empieza la acción!
2.1.3 Escribiendo un script
Aprovechemos para dar un nombre a los áreas que vemos en RStudio:
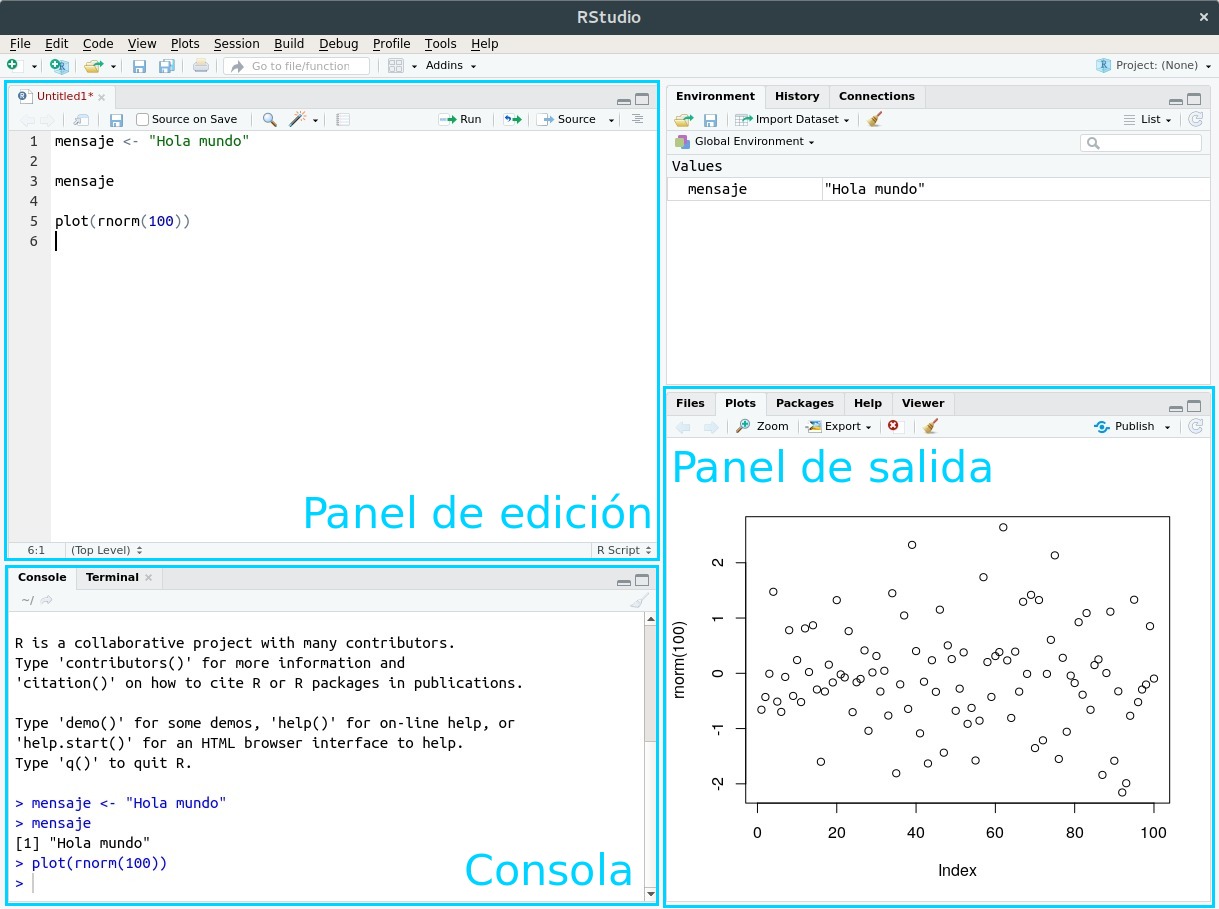
Figura 2.2: La interfaz de RStudio
Vamos a escribir nuestro código (las instrucciones que R entiende) en el panel de edición. Los resultados van a aparecer en la consola (cuando se trate de texto) o en el panel de salida (cuando produzcamos gráficos)
Por ejemplo, podemos escribir el panel de edición la instrucción para mostrar el resultado de una operación matemático:
sqrt() es una función. En el mundo de la programación, las funciones son secuencias de código ya listas para usar, que realizan tareas útiles. Por ejemplo, mostrar algo en pantalla. En nuestro caso, completamos la función con algo más: un parámetro, pues así se le llama a los valores que una función espera de parte del usuario para saber que hacer. La función sqrt() espera que le demos un número para el cual calcular su raíz cuadrada (square root en inglés), y eso hicimos: le pasamos cómo parámetro 144, un número. Los parámetros siempre se escriben entre paréntesis, a continuación del nombre de la función.
Ahora vamos a aprender la combinación de teclas más importante al usar RStudio: Ctrl + Enter. Presionar Ctrl + Enter al terminar de escribir una instrucción hace que RStudio la ejecute de inmediato, y espere en la siguiente instrucción, si la hubiera.
También podemos buscar una línea que deseemos ejecutar, posicionando el cursor de texto (que luce como una barra vertical que titila, en el panel de edición) sobre ella. Si a continuación pulsamos Ctrl + Enter, la línea será ejecutada y el cursor se moverá sólo hasta la siguiente línea, listo para repetir el proceso.
La modalidad de ejecución línea por línea es muy útil para lo que se llama “análisis interactivo”. Uno ejecuta un comando, observa el resultado, y en base a eso decide su próxima acción: cambiar parámetros e intentarlo de nuevo, dar por buenos los resultados y usarlos para una tarea subsiguiente… etc.
Por ejemplo, si escribimos las siguientes líneas:
…y posicionamos el cursor en cualquier posición de la primera línea, para luego pulsar Ctrl + Enter tres veces, veremos que las instrucciones son ejecutadas línea a línea.
## [1] 12## [1] "Hola mundo"Dos de ellas (la primera y la última) mostraron una salida en pantalla, y la del medio, no. Esto es porque algunas funciones entregan algo como resultado algo -un número, un texto, un gráfico, u otros tipos de salida que ya veremos- mientras que otras hacen su tarea silenciosamente sin expresar nada. En este caso, la función silenciosa fue la de asignación: mensaje <- "Hola mundo" es una instrucción que le pide a R que cree una variable llamada “mensaje” (o que la encuentre si ya existe) y que le asigne como valor el texto “Hola mundo”. ¿Cómo sabemos que la instrucción se llevó a cabo, a pesar de no producir una salida? En general, es un tema de confianza. Si una instrucción no genera un mensaje de error, si es silenciosa, se asume que pudo cumplir su cometido. En este caso, además lo hemos verificado. La línea final, mensaje pide a R que busque la variable, y muestre en pantalla su contenido (esa es una característica muy práctica del lenguaje: para saber el contenido de una variable, basta con escribirla y ejecutar la línea). Y al hacerlo, comprobamos que la variable contiene precisamente lo que hemos tipeado.
De paso, hay que mencionar que la creación y manipulación de variables es un concepto clave en programación. Trabajar con variables nos permite almacenar valores para usarlos después, además de hacer nuestro código más fácil de leer y compartir con otros, en especial cuando usamos nombre de variable auto-explicativos. Como ejemplo de ésto ultimo comparemos
## [1] 48… con
ancho_habitacion_m <- 8
profundiad_habitacion_m <- 6
superficie_habitacion_m2 <- ancho_habitacion_m * profundiad_habitacion_m
superficie_habitacion_m2## [1] 48En su resultado ambas expresiones son iguales, dado que producen lo mismo. Pero la segunda esta escrita de una forma mucho más clara para un ser humano, que hace más fácil interpretar su lógica… ¡está calculando la superficie en metros cuadrados de una habitación!. Es muy importante escribir nuestro código de la forma más explícita posible, aunque requiera tipear un poco más. Con ello, le hacemos la vida más fácil a otras personas que interpreten nuestros programas. Y también a nosotros mismos en el futuro, cuando debamos lidiar con un programa que escribimos tiempo atrás y del que a duras penas recordamos su lógica.
A todo esto… ¿no se suponía que íbamos a investigar la mortalidad infantil en la Ciudad de Buenos Aires?. Suficiente introducción… ¡allá vamos!
2.1.4 Cargar los datos
Vamos a cargar datos de mortalidad infantil, por comuna de la ciudad, en el año 2016, publicados por la Dirección General de Estadística y Censos de Buenos Aires. El formato original de los datos es “.xls” (planilla de hojas de cálculo). Yo lo he convertido a .csv (“comma separated values”) un formato muy popular en el mundo de la ciencia de datos, ya que es muy fácil de manipular y compartir entre sistemas… es posible abrir un archivo .csv hasta con el humilde block de notas. Al igual que los archivos .xls, los .csv se utilizan para guardar información tabular: un rectángulo con filas y columnas. R incluye una función que lee archivos .csv, que se llama read.csv. La usamos así:
Obsérvese que los datos están alojados en un servidor de internet (accesibles vía una dirección web). Eso no es problema para la función read.csv(), que con la misma soltura lee archivos guardados en nuestra PC o publicados en un sitio online.
Una vez leído el archivo, para ver el contenido de la variable donde guardamos el resultado -que hemos llamado mortalidad- sólo hace falta escribir su nombre:
## Comuna Tasa2016
## 1 1 9.5
## 2 2 3.6
## 3 3 8.0
## 4 4 11.9
## 5 5 8.5
## 6 6 2.4
## 7 7 8.5
## 8 8 9.7
## 9 9 10.1
## 10 10 3.6
## 11 11 6.2
## 12 12 7.1
## 13 13 4.5
## 14 14 3.2
## 15 15 6.4Vemos que la tabla tiene 15 filas (una por cada comuna de la ciudad) y 2 columnas (una que indica la comuna, y otra con el valor de mortalidad infantil para el año 2016).
En R, las tablas son llamadas dataframes. El dataframe es el objeto por excelencia del análisis de datos. En concepto, es muy similar a una tabla de Excel; al fin y al cabo, ambos formatos guardan información en celdas identificadas por fila y columna.
Algunas funciones útiles para explorar un dataframe que no conocemos son dim(), que nos da las dimensiones del dataframe (cantidad de filas y columnas), names() que nos dice como se llaman sus columnas (que en general representan variables), y head() que nos permite echar un vistazo rápido al contenido, mostrando sólo las seis primeras filas (ésto es útil porque con frecuencia trabajamos con dataframes que contienen miles o millones de filas, con lo que no tiene sentido tratar de volcar todas en pantalla).
## [1] 15 2## [1] "Comuna" "Tasa2016"## Comuna Tasa2016
## 1 1 9.5
## 2 2 3.6
## 3 3 8.0
## 4 4 11.9
## 5 5 8.5
## 6 6 2.4