Capítulo 4 Visualización
La visualización de información es una de las técnica más poderosas, y a la vez más accesibles, de las que disponemos como analistas de datos. La visualización es el proceso de hacer visibles los contrastes, ritmos y eventos que los datos expresan, que no podemos percibir cuando vienen en forma de áridas listas de números y categorías.
Vamos a aprender a realizar las visualizaciones más usadas, y las opciones de ajuste con las que podemos lograr que luzcan tal como queremos.
4.1 Una buena visualización para empezar: el scatterplot
Los gráficos de dispersión, o scatterplots, son quizás el tipo de visualización más conocido. Consisten en puntos proyectados en un eje de coordenadas, donde cada punto representa una observación. Son útiles para mostrar la correlación entre dos variables numéricas.
Por ejemplo, podríamos asumir que existirá una correlación positiva entre la cantidad de habitantes de una comuna y la cantidad de contactos anuales que sus habitantes hacen a las líneas de atención al ciudadano. Es decir, cuantas más personas vivan en una comuna, es de esperarse que sea mayor la cantidad de quejas, denuncias, etc. que se originan allí.
Activamos el paquete tidyverse, si aún no lo habíamos hecho.
library(tidyverse)Y si no lo tenemos ya cargado, leemos de nuevo el dataframe con los registros de atención al ciudadano (esta versión incluye la columna “COMUNA”).
atencion_ciudadano <- read.csv("http://bitsandbricks.github.io/data/gcba_suaci_comunas.csv")Usando los verbos de transformación que aprendimos, es fácil obtener un dataframe resumen con los totales anuales por comuna. Vamos a expresar los totales en miles de contactos, para evitar trabajar con números tan grandes.
contactos_por_comuna <- atencion_ciudadano %>%
group_by(COMUNA) %>%
summarise(miles_contactos = sum(total) / 1000 )
contactos_por_comuna## # A tibble: 16 x 2
## COMUNA miles_contactos
## <int> <dbl>
## 1 1 685.
## 2 2 48.8
## 3 3 71.2
## 4 4 94.5
## 5 5 77.1
## 6 6 82.8
## 7 7 95.8
## 8 8 61.3
## 9 9 91.2
## 10 10 114.
## 11 11 139.
## 12 12 123.
## 13 13 106.
## 14 14 99.3
## 15 15 107.
## 16 NA 5.78Lo que nos falta ahora es la cantidad de habitantes en cada comuna. No problem. El dato es fácil de conseguir, otra vez cortesía de la Dirección General de Estadística y Censos de la Ciudad de Buenos Aires. Traemos la proyección al año 2017 de la cantidad de habitantes por comuna.
habitantes <- read.csv("http://bitsandbricks.github.io/data/gcba_pob_comunas_17.csv")
habitantes## COMUNA POBLACION
## 1 1 253271
## 2 2 149720
## 3 3 192763
## 4 4 238809
## 5 5 186956
## 6 6 184846
## 7 7 240607
## 8 8 226649
## 9 9 170605
## 10 10 170282
## 11 11 189986
## 12 12 213914
## 13 13 235967
## 14 14 226944
## 15 15 182409Por suerte, ya sabemos como combinar tablas usando left_join()
contactos_por_comuna <- contactos_por_comuna %>% left_join(habitantes)
contactos_por_comuna## # A tibble: 16 x 3
## COMUNA miles_contactos POBLACION
## <int> <dbl> <int>
## 1 1 685. 253271
## 2 2 48.8 149720
## 3 3 71.2 192763
## 4 4 94.5 238809
## 5 5 77.1 186956
## 6 6 82.8 184846
## 7 7 95.8 240607
## 8 8 61.3 226649
## 9 9 91.2 170605
## 10 10 114. 170282
## 11 11 139. 189986
## 12 12 123. 213914
## 13 13 106. 235967
## 14 14 99.3 226944
## 15 15 107. 182409
## 16 NA 5.78 NA!Preparativos terminados! Hagamos por fin nuestro scatterplot. Tal como en el capítulo de introducción a R, continuaremos usando ggplot() para visualizar:
ggplot(contactos_por_comuna)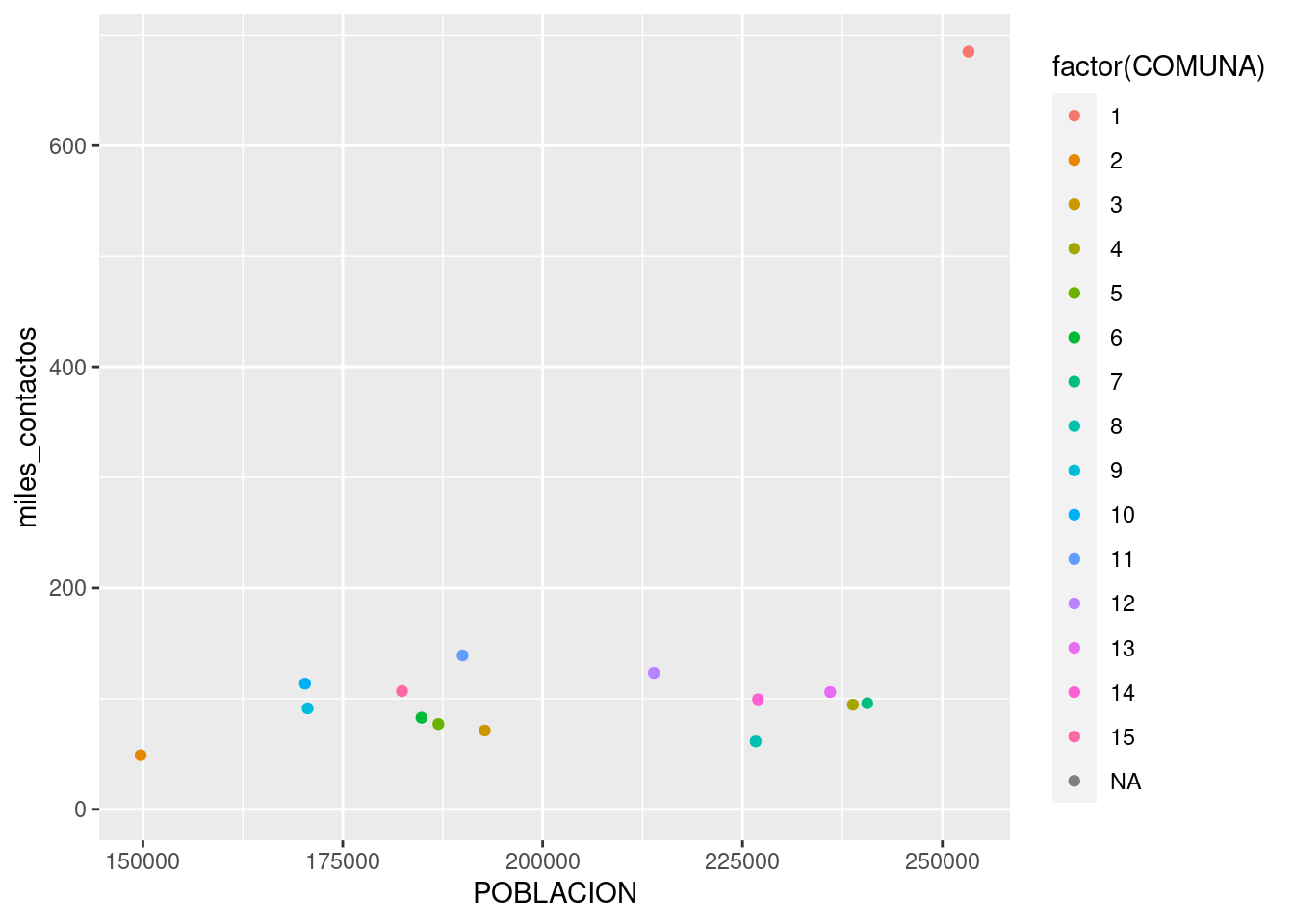
¿Un gráfico vacío? Recordemos que ggplot funciona por capas. Primero uno declara el dataframe que va a usar, y luego agrega una o más capas con representaciones de la información. La forma de agregar una capa con un scatterplot, en la práctica dibujar puntos, es con geom_point:
ggplot(contactos_por_comuna) + geom_point(aes(x = POBLACION, y = miles_contactos))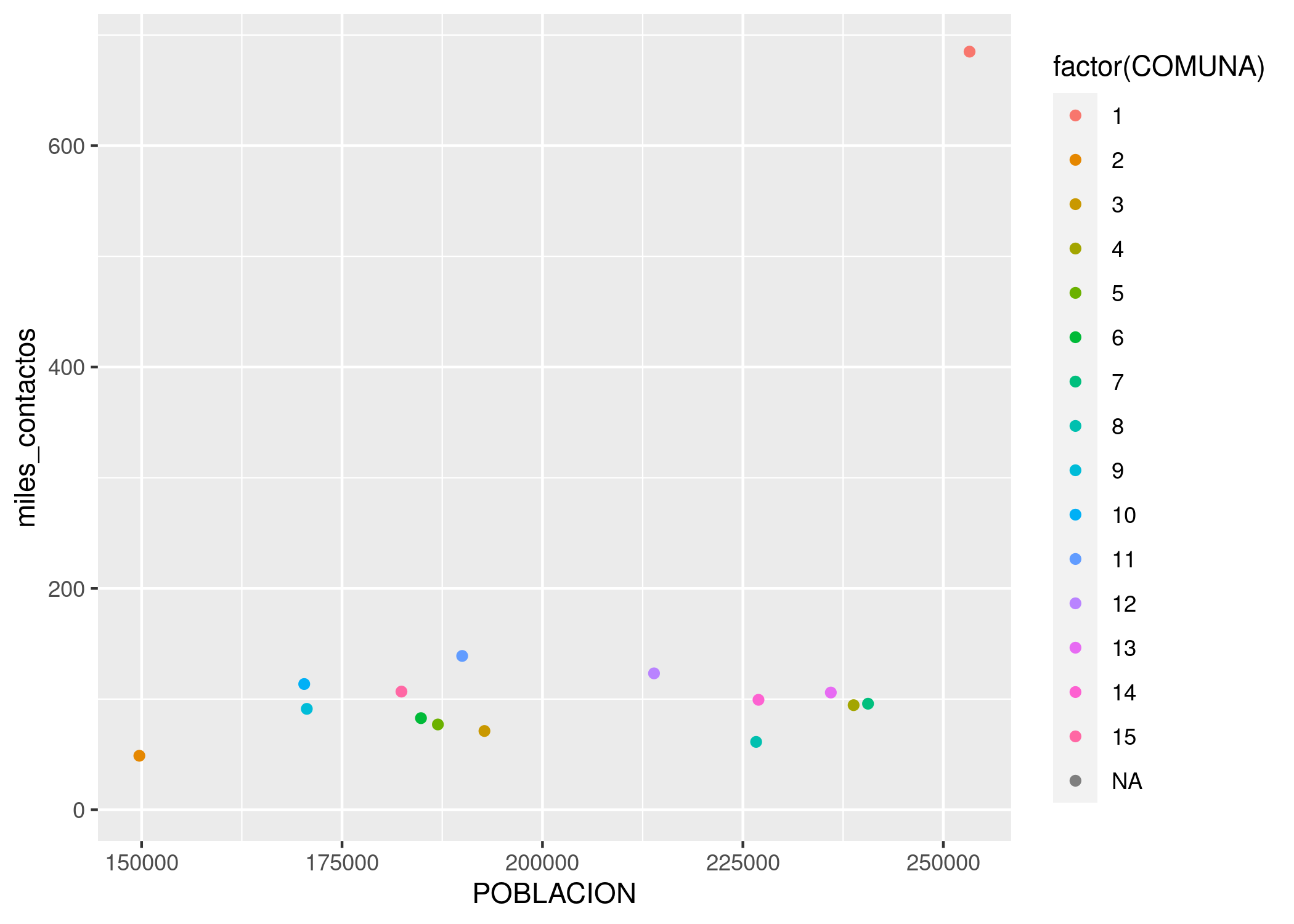
Lo que hicimos fue pedirle a ggplot que dibuje un punto por cada fila (representando a cada comuna), con la posición en el eje de las x según su población, y en el eje de las y según la cantidad de contactos registrados. Estas referencias estéticas (aesthetics en inglés) son las que van dentro de la función aes() en geom_point(aes(x = POBLACION, y = miles_contactos))
Primer sorpresa: ¡en el extremo superior derecho hay una comuna que se sale de la norma! Su relación población/reclamos es muy diferente a la de todas las demás. Podemos identificarla, pidiendo a ggplot que agregue una variable más a la visualización -la comuna. Siendo un gráfico en dos dimensiones, ya no podemos usar la posición para representar un valor; tanto la posición horizontal como la vertical están siendo usadas por población y total. Nuestras opciones son codificar la comuna por color, forma o tamaño del punto. A pesar de que son identificadas con números, las comunas son una variable categórica: no tiene sentido decir que la comuna 1 es “menor” que la comuna 7. Par las variables categóricas, el color suele ser una buena opción de codificación.
Lo hacemos agregando un parámetro color dentro de aes(). Tal como hicimos en el capítulo 2, usamos factor(COMUNA) en lugar de COMUNA a secas para indicarle a R que queremos que trate a la variable como categórica:
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos, color = factor(COMUNA)))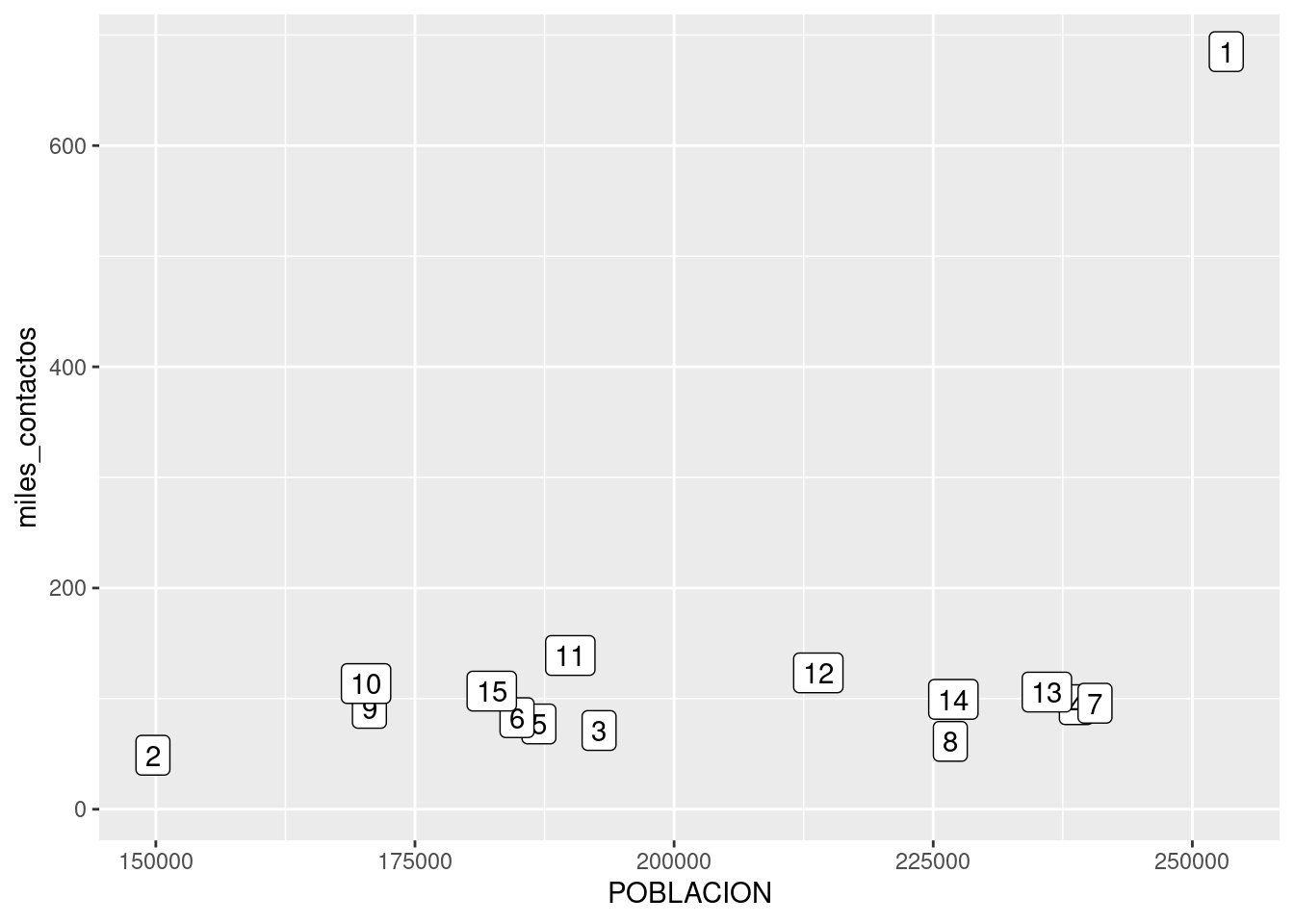
En ese caso, no es tan fácil discernir cuál es cuál, pero mirando con cuidado descubrimos que la comuna 1 es el outlier, el valor fuera de lo común. Lo que nos pasa aquí es que tenemos demasiadas categorías, con lo cual cada una tiene su propio color pero el rango cromático no alcanza para darle a cada una un tono bien distinto al de las demás.
Si necesitamos generar un gráfico que no deje lugar a dudas, lo resolvemos usando un método alternativo para el scatterplot. En lugar de dibujar puntos, podemos poner etiquetas con el nombre de cada comuna.
En lugar de
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos, color = factor(COMUNA)))usamos
ggplot(contactos_por_comuna) +
geom_label(aes(x = POBLACION, y = miles_contactos, label = factor(COMUNA)))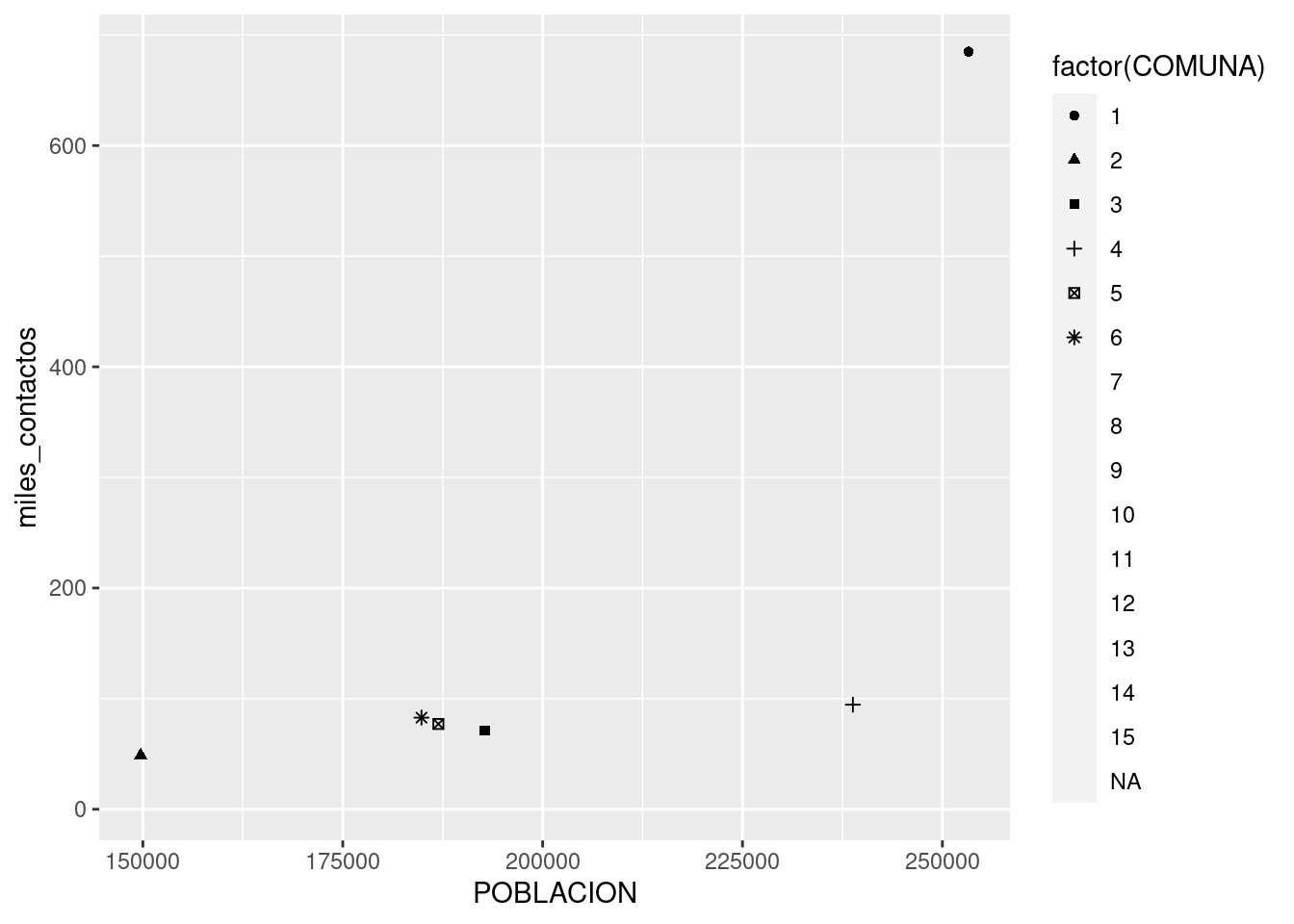
Volvamos a nuestros puntos para practicar dos codificaciones estéticas que no hemos probado, color y tamaño.
Para dejar aún más clara la diferencia de reclamos entre comunas, podríamos usar el tamaño (size) de cada punto para representar esa variable, además de su altura en el gráfico.
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos, size = miles_contactos))
Y para distinguir cuál es cuál, podemos pedirle a ggplot que cambie la forma (shape) de cada punto según la comuna a la que corresponde.
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos, shape = factor(COMUNA)))
¡Hey, sólo aparecen seis de las comunas! ggplot() usa cómo máximo 6 formas distintas, debido a que una cantidad mayor sería de veras muy difícil de discernir para nuestros pobres ojos. Moraleja: la estética shape sirve sólo cuando manejamos pocas categorías. De todas formas -en mi opinión- es el método de codificación que menos gracia tiene, así que no es grave que su utilidad sea limitada.
4.2 Ajustando color y tamaño
Hemos visto que especificando atributos estéticos y las variables que representan dentro
de aes() podemos ajustas posición, tamaño, color y hasta la forma de los puntos de acuerdo a sus valores. Pero, ¿qué pasa si queremos usar un tamaño o un color arbitrario para nuestros puntos? Es decir, si no nos gusta el color negro y queremos que sean todos azules, o si nos parece que se ven pequeños y queremos que sean todos un poco más grandes. Fácil: definimos el color o size que queremos por fuera de las función aes(), y será aplicado a todos los puntos.
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos), color = "blue")
Obsérvese que color = "blue" está escrito por fuera de los paréntesis de aes(). De paso, hicimos uso de una característica muy práctica de R: reconoce un montón de colores por su nombre, siempre que los escribamos entre comillas. Si le decimos color = "blue", color = "red", color = "yellow", etc., sabe de que hablamos. Una lista de todos los colores que R reconoce, ideal como referencia, se puede encontrar en http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf ; ¡son más de 600!.
Tras un vistazo a la lista, me decido por “darkolivegreen4”:
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos), color = "darkolivegreen4")
Bellísimo.
En cuanto al tamaño, la fórmula es la misma:
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos), size = 5)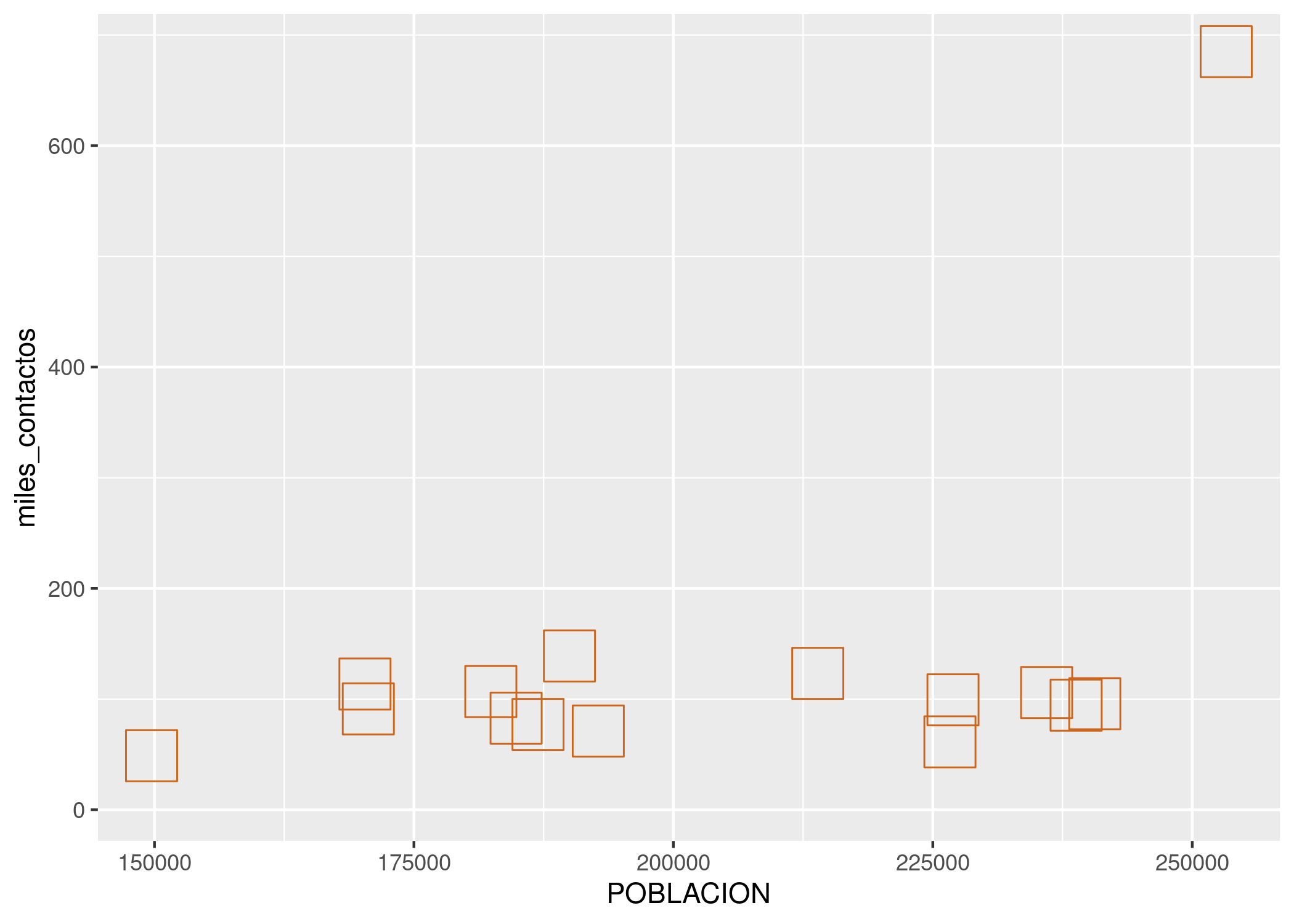
El valor de size se da en píxeles. Es una medida difícil de estimar antes de ver el resultado, pero es cuestión de probar algunos valores distintos hasta encontrar el que nos va bien. Por supuesto, podemos ajustar varios, o todos, los atributos a la vez
ggplot(contactos_por_comuna) +
geom_point(aes(x = POBLACION, y = miles_contactos),
size = 9, color = "chocolate3", shape = 0)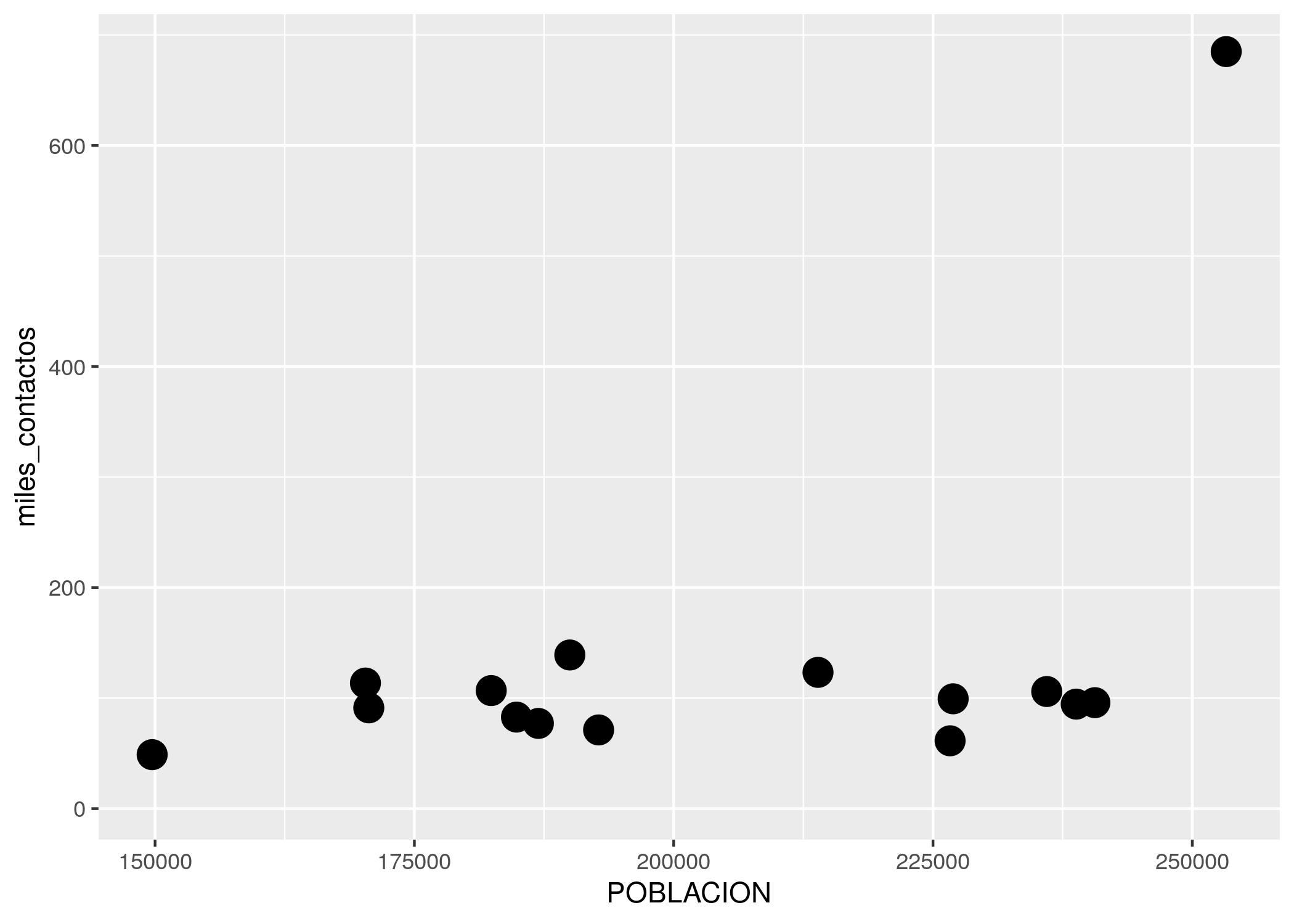
4.3 Facetado
Ya sabemos como representar variables usando atributos estéticos. Con esa técnica podemos mostrar con claridad dos o tres variables en un plano bidimensional (nuestro gráfico). Pero cuando si queremos agregar más atributos para codificar variables adicionales, la visualización pierde legibilidad de inmediato. Por suerte existe otra técnica, que podemos usar en combinación con la estética, para agregar aún más variables: el facetado.
Las facetas son múltiples gráficos contiguos, con cada uno mostrando un subconjunto de los datos. Son útiles sobre todo para variables categóricas.
Practiquemos con un ejemplo. Sabemos que en la comuna 1 se registra una cantidad de contactos de la ciudadanía mucho mayor que en las demás. ¿La diferencia será igual para todas las categorías de contacto, o existe alguna en particular que es la que inclina la balanza?
En nuestro dataframe original, el tipo de contacto aparece en la columna “TIPO_PRESTACION”. El nombre que eligieron no es del todo informativo, pero summary() (recuerden siempre lo usamos para explorar un dataset que no conocemos) nos da una pista:
summary(atencion_ciudadano)## PERIODO RUBRO TIPO_PRESTACION
## Min. :201301 SANEAMIENTO URBANO : 4589 DENUNCIA :21606
## 1st Qu.:201309 TRANSPORTE Y TRANSITO: 4580 QUEJA : 3914
## Median :201404 ARBOLADO : 3122 RECLAMO :21038
## Mean :201401 ALUMBRADO : 2918 SOLICITUD: 9662
## 3rd Qu.:201503 PAVIMENTO : 2411 TRAMITE : 1211
## Max. :201512 ESPACIO PUBLICO : 1918
## (Other) :37893
## BARRIO total COMUNA AÑO
## Length:57431 Min. : 1.00 Min. : 1.000 Length:57431
## Class :character 1st Qu.: 1.00 1st Qu.: 4.000 Class :character
## Mode :character Median : 4.00 Median : 9.000 Mode :character
## Mean : 34.85 Mean : 8.119
## 3rd Qu.: 16.00 3rd Qu.:12.000
## Max. :19221.00 Max. :15.000
## NA's :63
## MES
## Length:57431
## Class :character
## Mode :character
##
##
##
## “TIPO_PRESTACION” es la categoría más general, con sólo cinco niveles - “DENUNCIA”, “QUEJA”, “RECLAMO”, “SOLICITUD” y “TRAMITE”. Las otras variables categóricas, asumimos, representan subtipos.
Agrupamos entonces nuestra data por comuna y por tipo de contacto, sin olvidar agregar luego los datos de población
contactos_por_comuna_y_tipo <- atencion_ciudadano %>%
group_by(COMUNA, TIPO_PRESTACION) %>%
summarise(miles_contactos = sum(total) / 1000 ) %>%
left_join(habitantes)
head(contactos_por_comuna_y_tipo)## # A tibble: 6 x 4
## # Groups: COMUNA [2]
## COMUNA TIPO_PRESTACION miles_contactos POBLACION
## <int> <fct> <dbl> <int>
## 1 1 DENUNCIA 22.9 253271
## 2 1 QUEJA 17.4 253271
## 3 1 RECLAMO 55.7 253271
## 4 1 SOLICITUD 20.9 253271
## 5 1 TRAMITE 568. 253271
## 6 2 DENUNCIA 10.2 149720Listos para facetar. Producimos un scatterplot igual que antes, y le agregamos una capa adicional con facet_wrap(). La variable a “facetar”, la que recibirá un gráfico por cada una de sus categorías, siempre se escribe a continuación del signo ~; en nuestro caso, queda como ~TIPO_PRESTACION. El simbolillo en cuestión denota lo que en R se denomina una fórmula y ya nos lo cruzaremos de nuevo, pero por ahora no le prestamos más atención.
ggplot(contactos_por_comuna_y_tipo) +
geom_point(aes(x = POBLACION, y = miles_contactos)) +
facet_wrap(~TIPO_PRESTACION)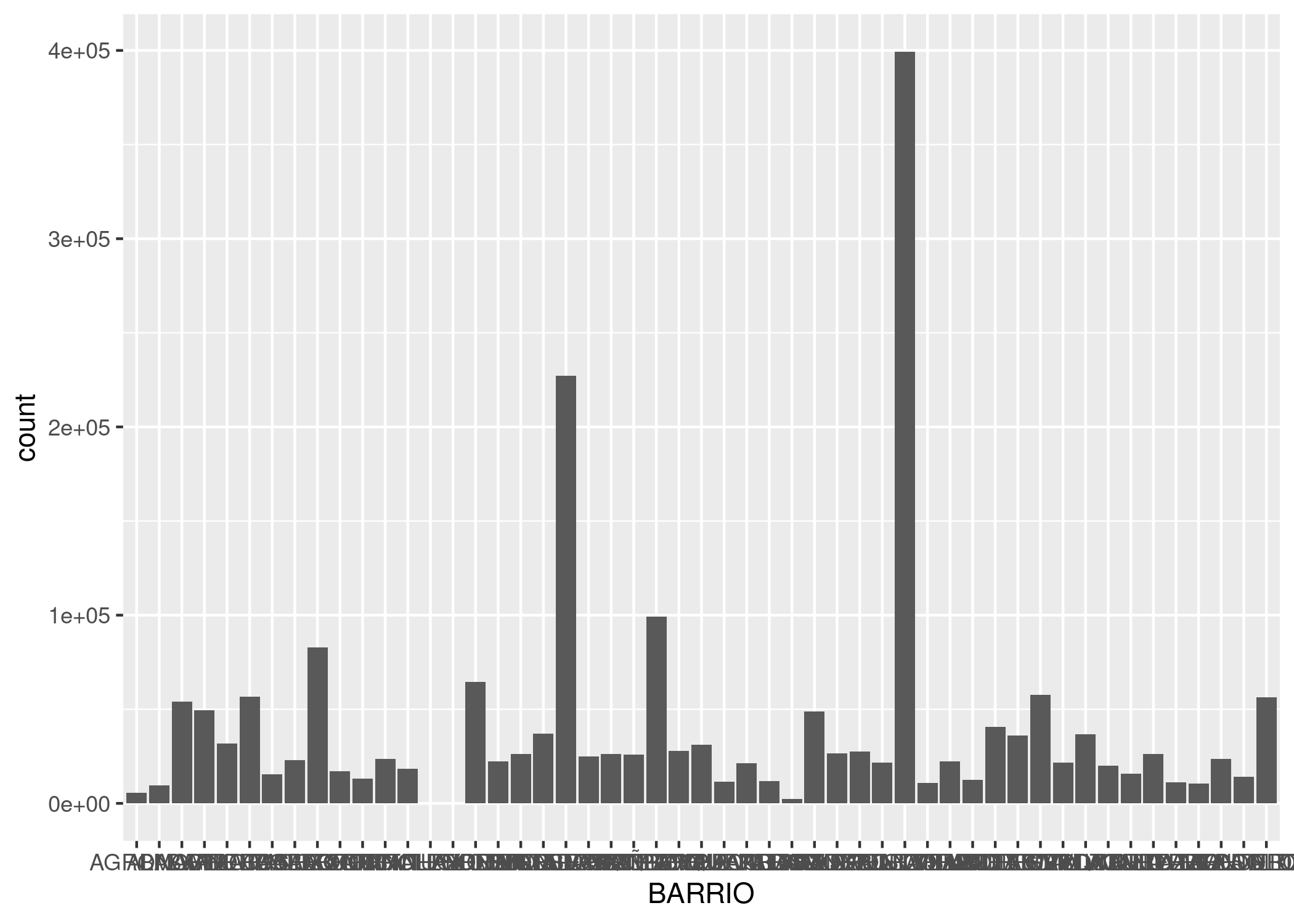
Los culpables de la anomalía son los trámites; en ninguna otra categoría la comuna 1 se separa del resto. Sabiendo que la base de donde provienen los datos combina información de distintos sistemas de atención, mi interpretación es que una gran cantidad de “TRAMITES” proviene de algún sistema administrativo que no guarda direcciones. Si ese fuera el caso, parece que a todos los trámites huérfanos de origen se les asigna una dirección en la Comuna 1 (sede histórica del Gobierno de la Ciudad) y nosotros terminamos haciendo estas elucubraciones.
Pero valga el ejemplo para mencionar algo fundamental: por más ciencia de datos que apliquemos, siempre vamos a llegar a un punto en que nuestros hallazgos no tendrán sentido sin combinarlos con lo que se llama “conocimiento de dominio”. El conocimiento de dominio es el saber especializado sobre el tema que estamos tratando, sea el ciclo reproductivo de la gaviota austral o la organización administrativa del Gobierno de la Ciudad Autónoma de Buenos Aires. Esto no debería desanimarnos, ¡al contrario!. El análisis de datos como profesión conlleva un constante aprendizaje sobre los más variados temas. Y a la inversa: si somos expertos en cualquier campo, aún con un puñado de técnicas básicas de R podemos extraer conocimiento de nuestros datos que jamas encontraría un experto programador que no conoce el paño.
4.4 Gráficos de barras
Si hay un tipo de visualización que compite en popularidad con el scatterplot, son los gráficos de barras (bar charts en inglés). Solemos encontrarlos acompañando artículos en diarios y revistas, sin duda porque son fáciles de leer de un vistazo. Los gráficos de barras se usan mucho para hacer comparaciones: quién tiene más y quién tiene menos de alguna variable continua cómo ingresos, edad, altura o similares.
Comparemos la suma total de registros que alcanza cada barrio. Con geom_bar podemos agregar una capa de visualizacón con gráficos de barras. Los parámetros a definir dentro de aes() son x, donde va una variable categórica, y en forma opcional weight, que indica la variable a sumar para determinar la altura de cada barra. Si no especificamos un weight, simplemente se cuenta cuantas veces aparece cada categoría en el dataframe, en la práctica un conteo o frecuencia de aparición. En nuestro dataset cada fila incluye un período y un total de contactos recibidos. Nosotros no estamos interesados en cuantas veces aparece cada barrio, sino en la suma de la columna total para cada uno de ellos, así que vamos a usar weight = total.
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total))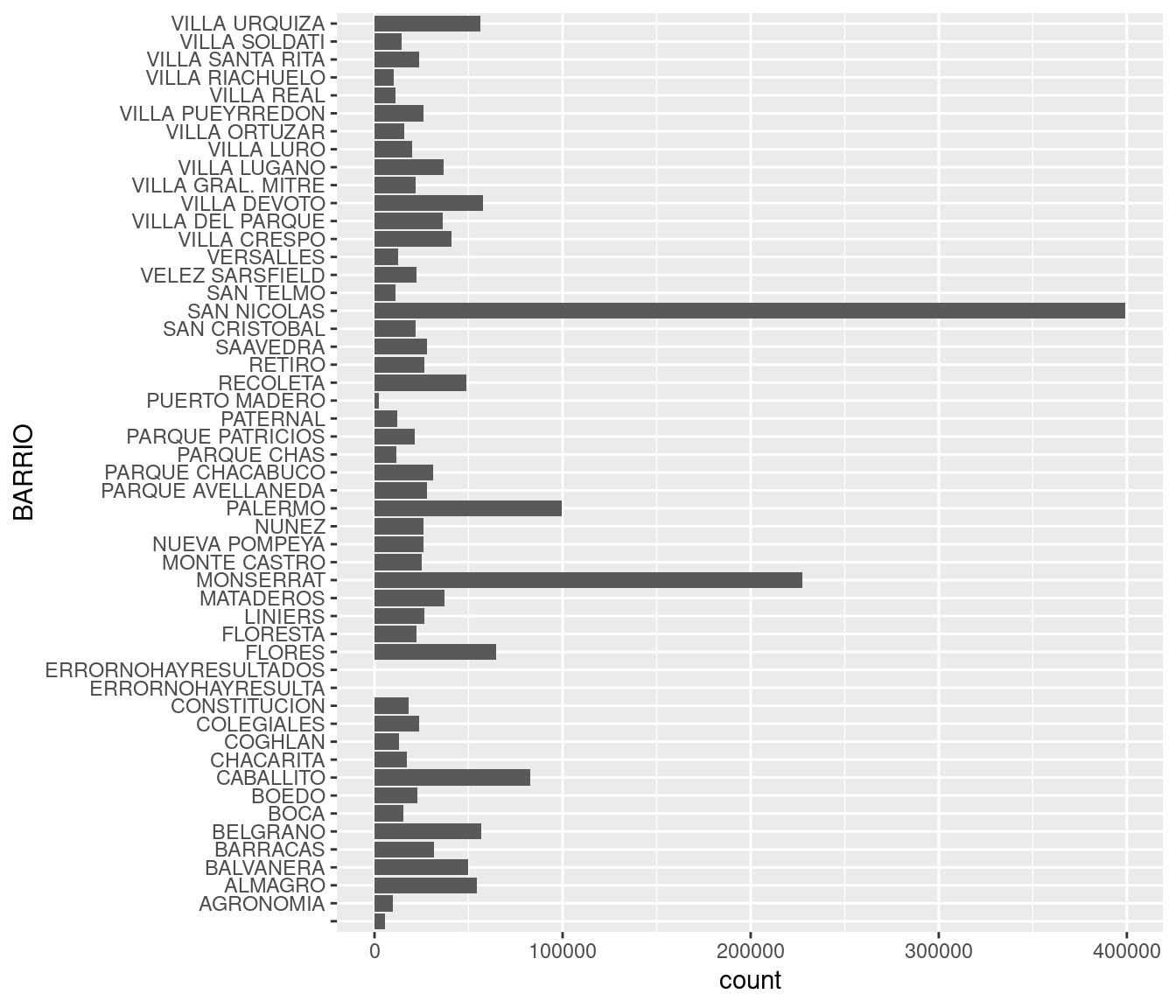
Tenemos dos problemas. El primero es que los valores en el eje de las y son grandes, y R nos quiere hacer un favor expresándolos en notación científica. La notación científica es práctica para ahorrar espacio, pero no queda vien en visualizaciones. Para pedirle que no lo haga mas, usamos esta función
options(scipen = 999)y por el resto de la sesión nos libramos de la notación científica. Listo.
El segundo problema es que los nombres de los barrios resultan del todo ilegibles porque no tienen espacio. En un gráfico, el eje horizonatal es un muy mal lugar para poner muchas categorías con nombre, ya que el solapamiento se vuelve inevitable. Sería mejor tener los nombre en el eje vertical, donde se pueden escribir uno encima del otro sin pisarse ¡La solución es invertir los ejes de de coordenadas! Sólo necesitamos agregar coord_flip:
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total)) +
coord_flip()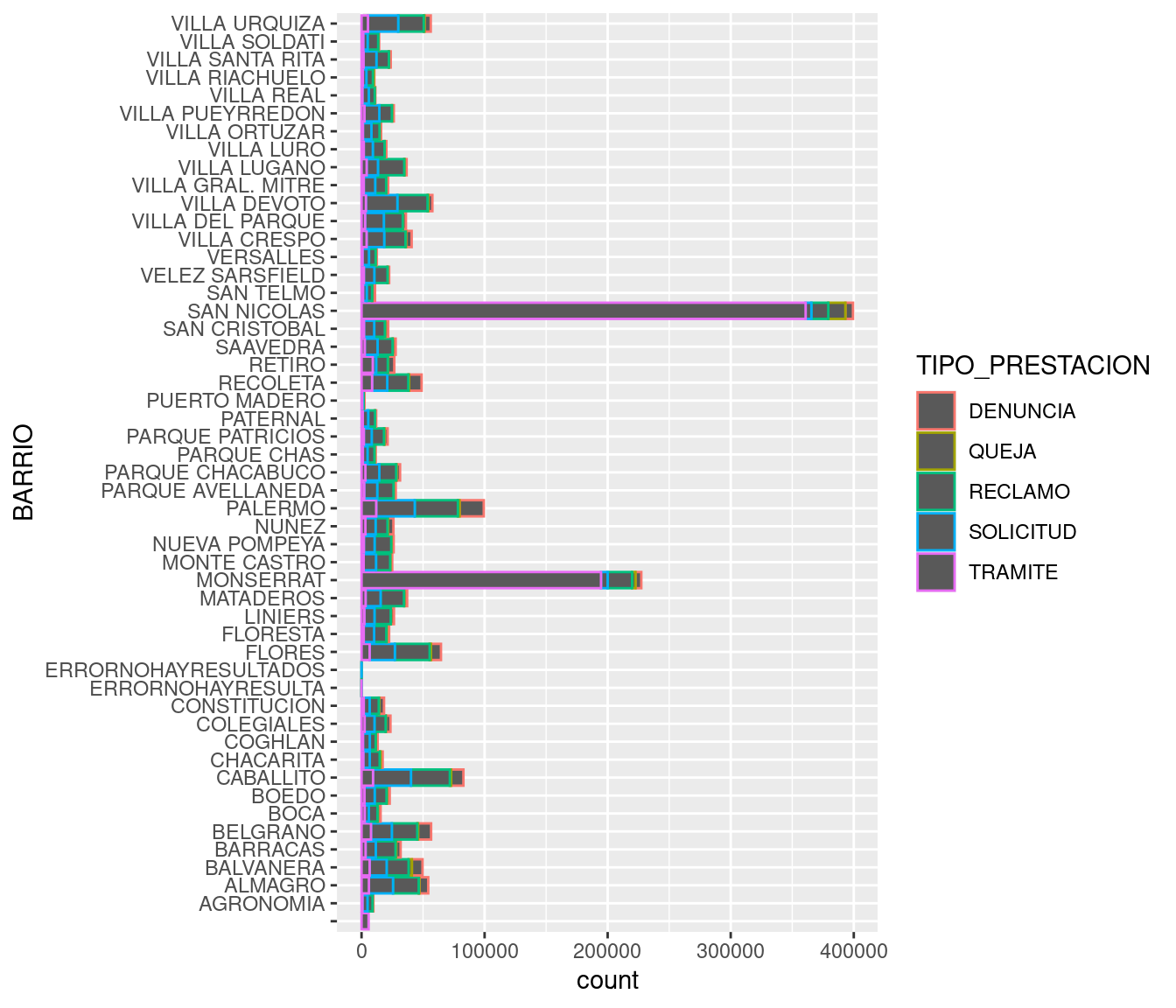
Ahora si podemos interpretar el gráfico. San Nicolás y Monserrat son los barrios a la cabeza, lo cual no sorprende sabiendo que pertenecen a la ya legendaria comuna 1.
Los gráficos de barras, además de comparar, también son buenos para mostrar la composición interna de las cosas: que “hay dentro”, que componentes contribuye a un determinado total. Vamos a mostrar entonces cuanto contribuye cada tipo de trámite al toal por barrio, usando el parámetro estético fill (relleno). geom_bar realiza un segmentado automático de cada barra, con la proporción que le corresponde a cada subcategoría:
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total, fill = TIPO_PRESTACION)) +
coord_flip()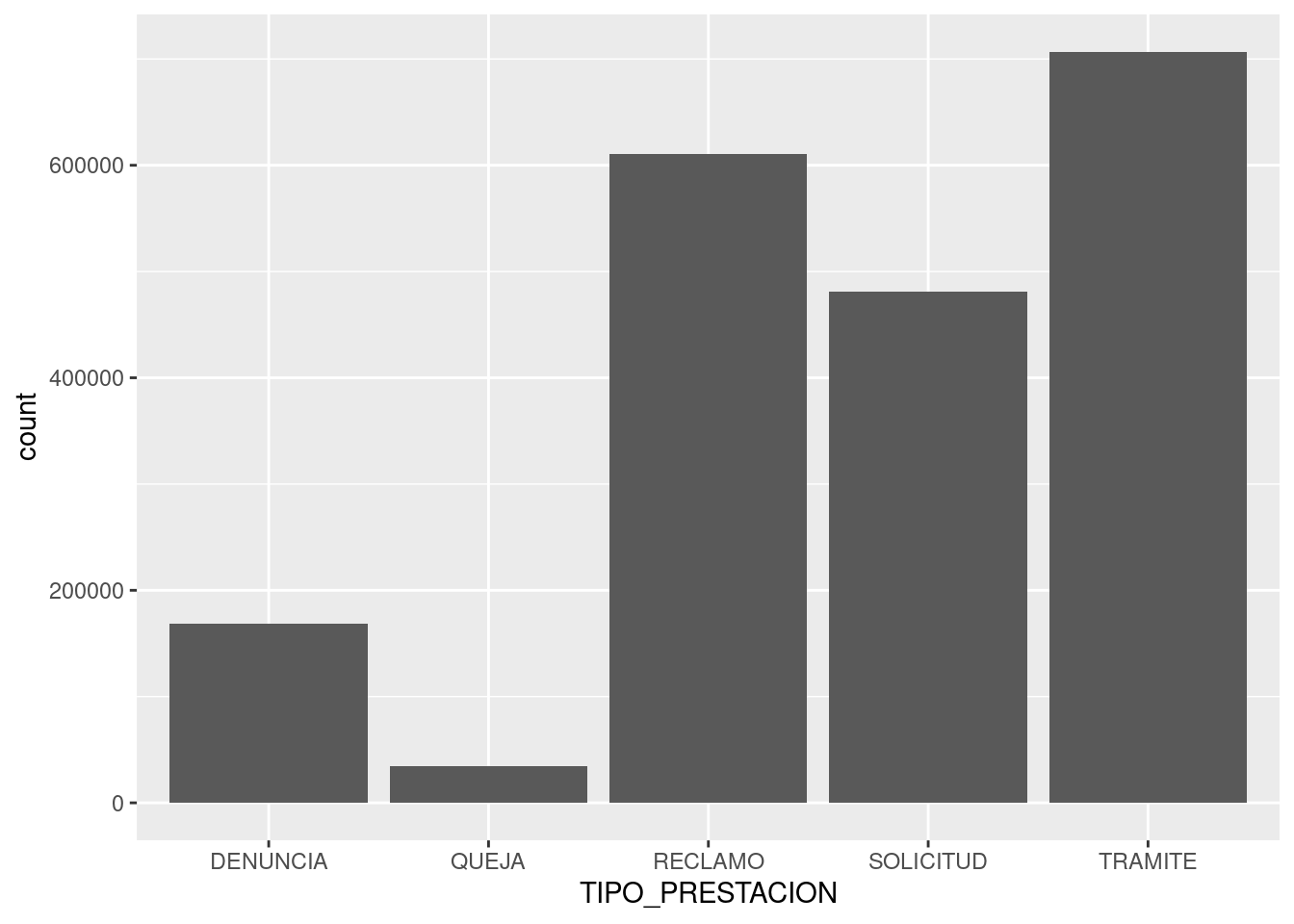
!Esos trámites otra vez! En cierto modo, estamos recorriendo las mismas conclusiones a las que arribamos usando scatterplots, pero mostrando la información de otra manera. De más está decirlo, hay muchas maneras de contar las cosas.
En lugar de relleno podríamos haber usado color, tal como hicimos con los puntos, pero los resultado es un poco menos legible y no luce tan bien. La variable color modifica la silueta de las barras, pero no su interior:
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total, color = TIPO_PRESTACION)) +
coord_flip()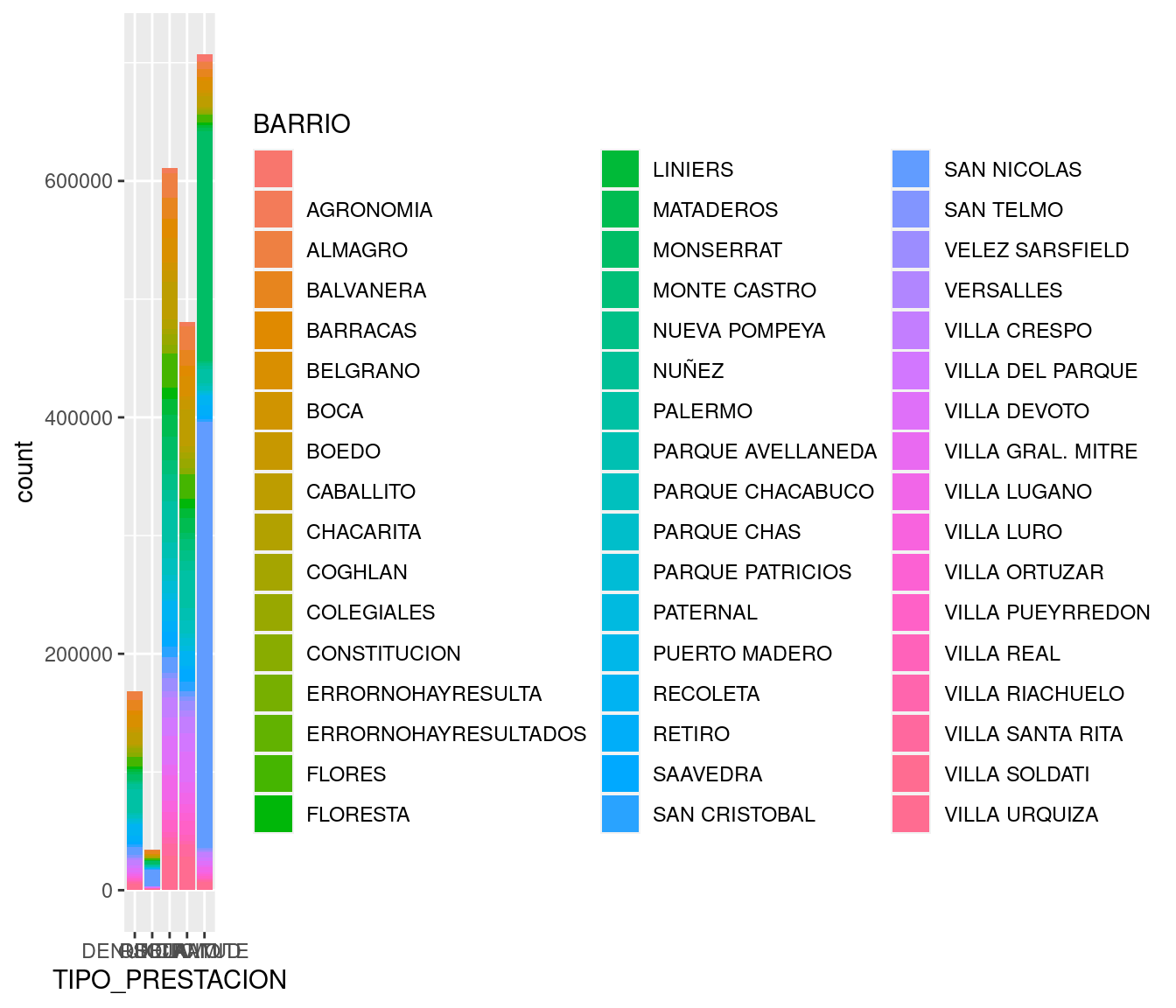
También podemos cambiar las categorías. Si qusiéramos ver el total de registros por cada tipo de trámite:
ggplot(atencion_ciudadano) +
geom_bar(aes(x = TIPO_PRESTACION, weight = total)) 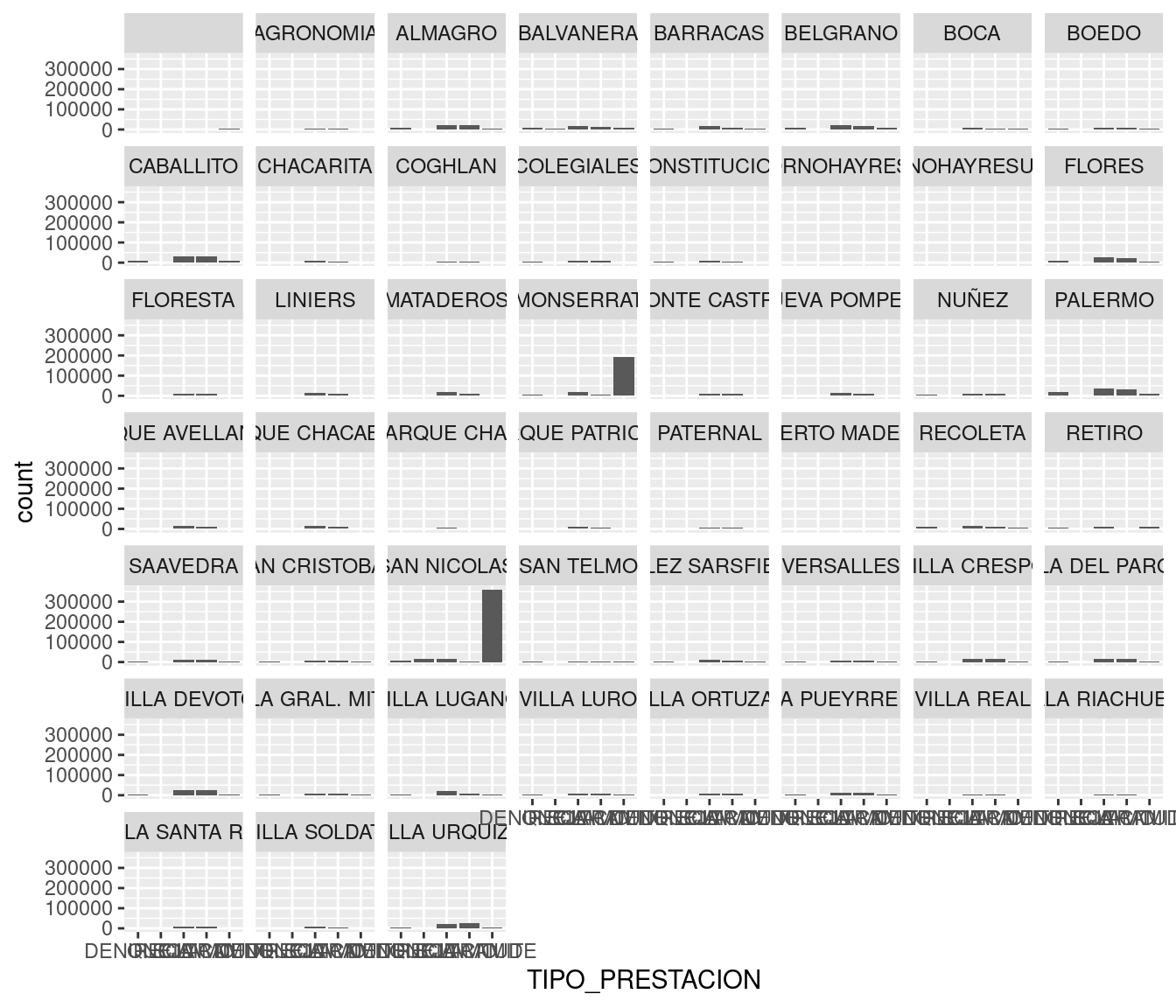
Notamos que las quejas y denuncias son eventos poco frecuentes en comparación con las otras clases de contacto entre ciudadanos y ciudad. En esta ocasión no recurrimos a coord_flip, ya que las categorías son pocas y tienen espacio suficiente en el eje horizontal.
¿Y si mostramos el aporte de cada barrio al total global de cada tipo de contacto?
ggplot(atencion_ciudadano) +
geom_bar(aes(x = TIPO_PRESTACION, weight = total, fill = BARRIO)) 
Hemos obtenido una visualización indigerible. Quizás con un facetado por barrio…
ggplot(atencion_ciudadano) +
geom_bar(aes(x = TIPO_PRESTACION, weight = total)) +
facet_wrap(~BARRIO)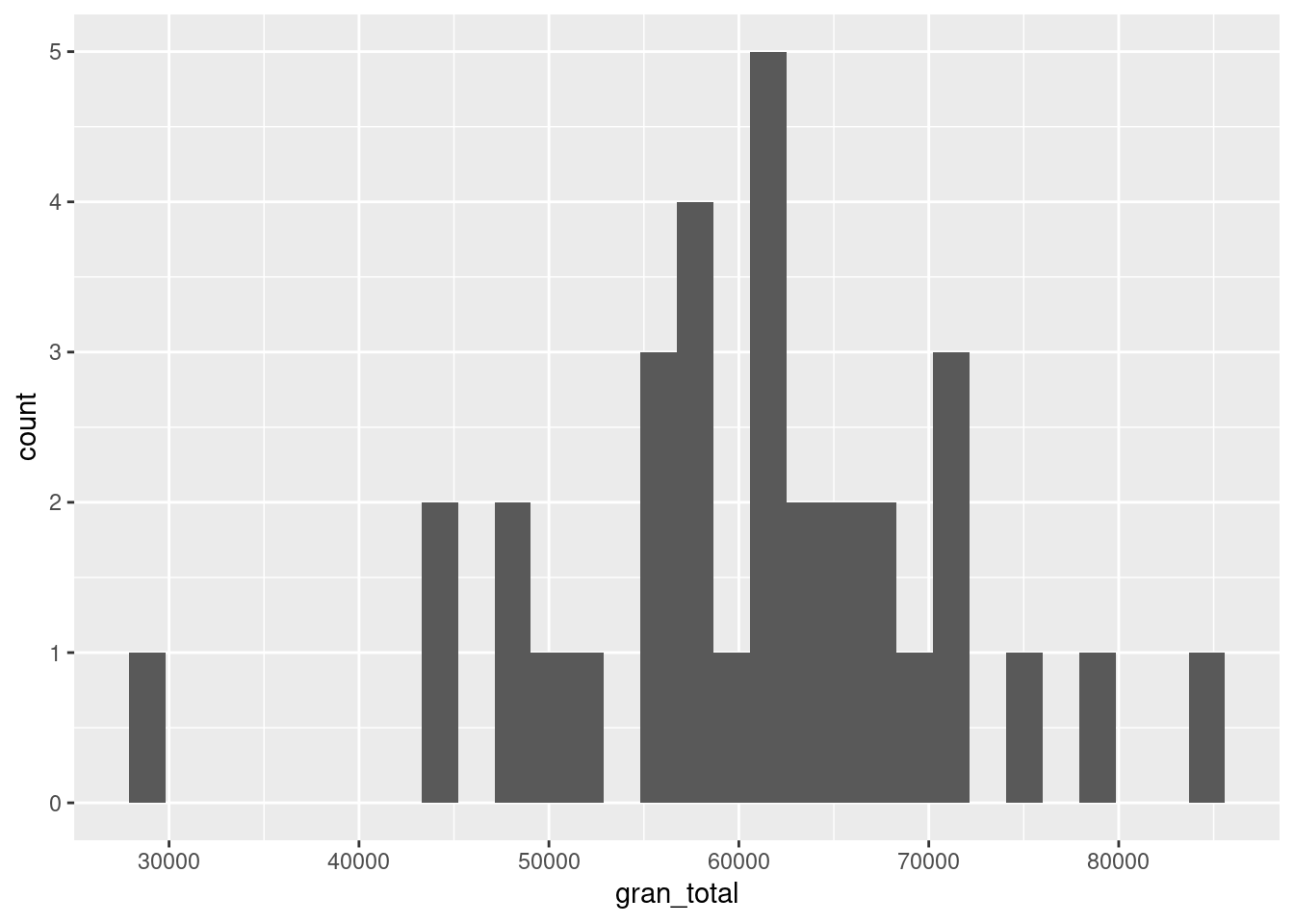
Esta opción es un poco mejor, ya que al menos permite identificar pronto los barrios salientes, y discernir diferencias generales si se la mira con paciencia. Una visualización tan densa en información puede resultar ideal para “uso personal”, explorando de forma rápida datos con los que estamos familiarizados, pero es poco recomendable para compartir con otros.
En general, para evitar la confusión asociada a variables con docenas de categorías se busca simplificar definiendo menos grupos. Por ejemplo, como hicimos al comienzo al separar por comunas, que son sólo quince, en lugar de por barrios.
4.5 Histogramas
Los histogramas son usados para mostrar la distribución de una variable continua. El histograma permite decir si los valores que toma cada observación se agrupan en torno a un valor “típico” o medio -como en el caso de la llamada distribución normal-, o en torno a dos valores frecuentes (distribución bimodal), o con dispersión sin picos ni valles, donde no hay valores típicos ni atípicos - distribución uniforme.
Por ejemplo, analicemos la distribución de resgistros mensuales (la columna PERIODO en nuestro datset representa el lapso de un mes). Tenemos que agrupar por mes, y hacer un resumen (summarise()) que extraiga el gran total:
contactos_por_mes <- atencion_ciudadano %>%
group_by(PERIODO) %>%
summarise(gran_total = sum(total))
head(contactos_por_mes)## # A tibble: 6 x 2
## PERIODO gran_total
## <int> <int>
## 1 201301 43826
## 2 201302 43666
## 3 201303 47405
## 4 201304 50768
## 5 201305 52761
## 6 201306 48344Hacer un histograma es simple con geom_histogram(): sólo hay que elegir una variable y asignarla a las x.
ggplot(contactos_por_mes) +
geom_histogram(aes(x = gran_total))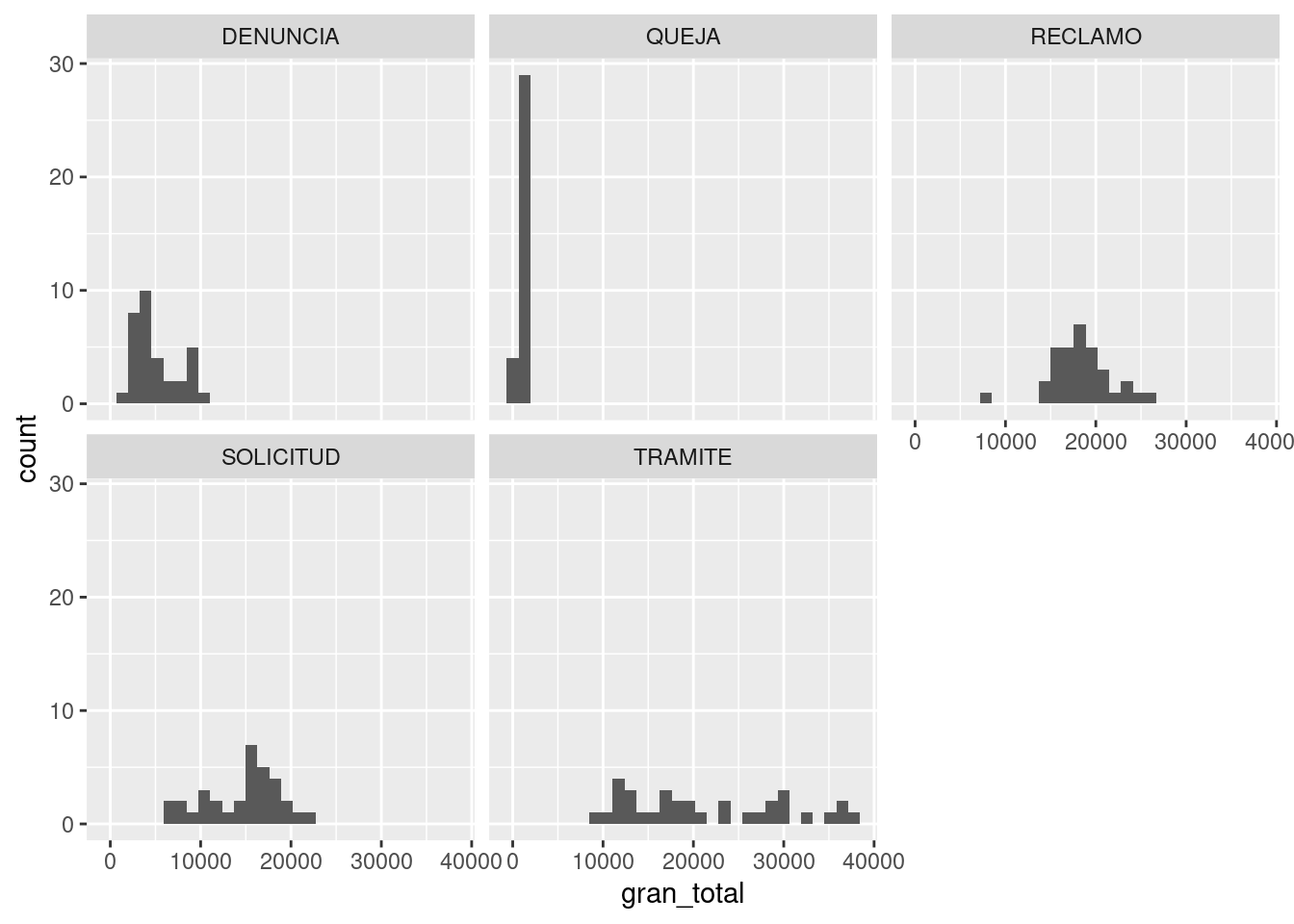
geom_histogram() divide el rango de valores en una cantidad arbitraria de segmentos iguales (“bins” en inglés) y cuenta cuantas observaciones caen en cada uno, cantidad que se representa con la altura de la columna en el eje de las y.
En nuestro ejemplo, vemos que un mes mes en el que la cantidad de resgitros tiende a agurparse en torno a un valor típico de poco más de 60.000 por mes. En apenas un caso hubo mennos de 40.000 o más de 80.000
No sería raro que la agregación qeu hicimos nos oculte patrones en los datos. Que pasa si contamos los registros por mes y por tipo de contacto, y mostramso los histogramas mensuales en facetado por tipo?
Hacemos el agrupado y sumario de rigor
contactos_por_mes_y_tipo <- atencion_ciudadano %>%
group_by(PERIODO, TIPO_PRESTACION) %>%
summarise(gran_total = sum(total))
head(contactos_por_mes_y_tipo)## # A tibble: 6 x 3
## # Groups: PERIODO [2]
## PERIODO TIPO_PRESTACION gran_total
## <int> <fct> <int>
## 1 201301 DENUNCIA 2740
## 2 201301 QUEJA 889
## 3 201301 RECLAMO 16011
## 4 201301 SOLICITUD 15325
## 5 201301 TRAMITE 8861
## 6 201302 DENUNCIA 2463y creamos el facetado como ya sabemos:
ggplot(contactos_por_mes_y_tipo) +
geom_histogram(aes(x = gran_total)) +
facet_wrap(~TIPO_PRESTACION)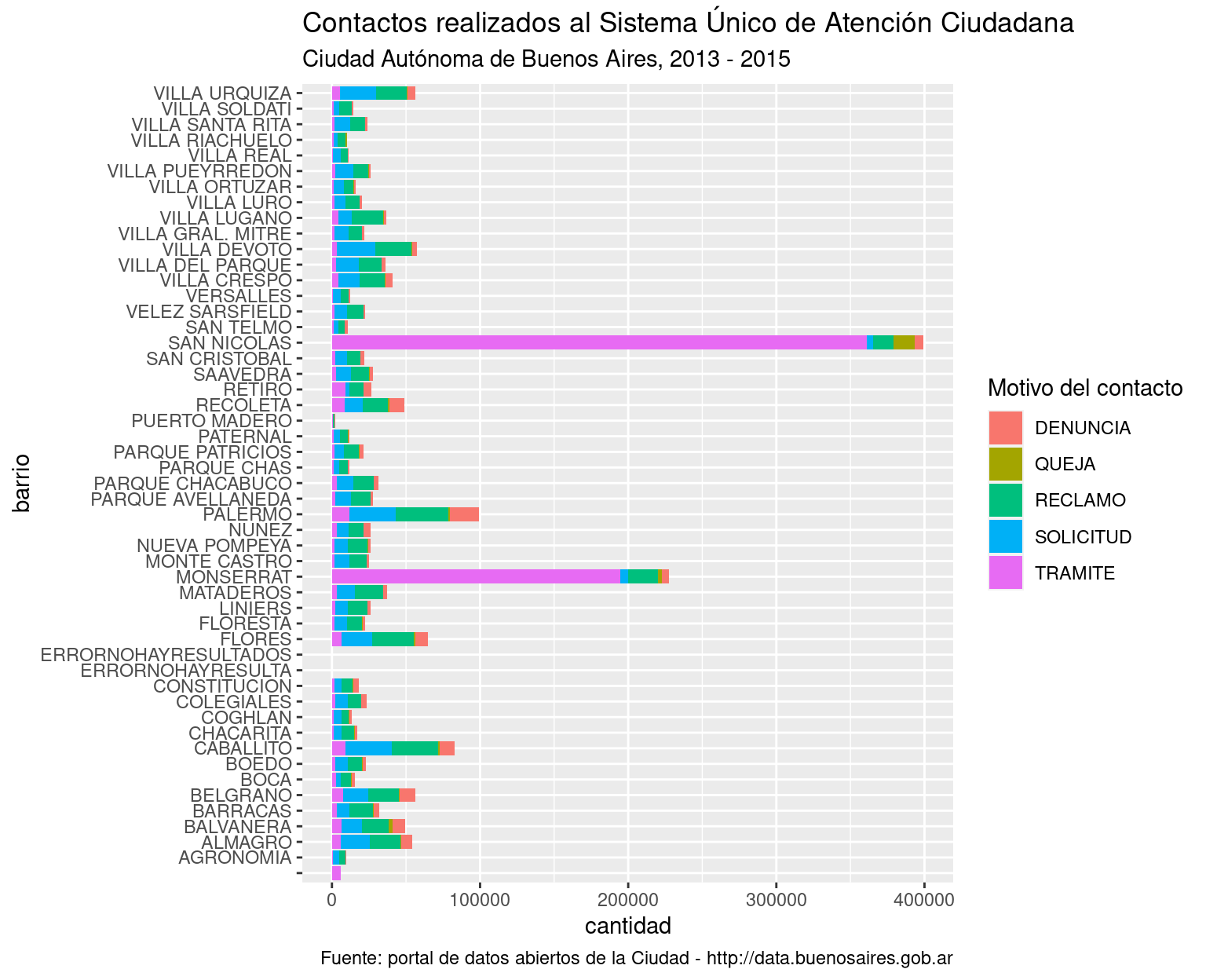
Aparecen las diferencias. Los reclamos tienen una dispersión mínima, con casi todas las observaciones apiladas en torno a unos 1000 contactos mensuales; siempre son bajas. La cantidad mensual de denuncias, reclamos y solicitudes muestra una dispersión mayor, pero aún así tendencia a rondar un valor típico. Los trámites son el extremo opuesto a las qeujas, ya que muestran una gran dispersión, pudiendo tomar cualquier valor de menos de 10.000 a más de 40.000 registros de forma bastante pareja.
4.6 Preparando una visualización para compartir
Lo último que nos queda por decir en este capítulo es que los gráficos que hemos producido hasta aquí están pensandos para nuestro propio consumo. Son parte, y parte dundamental, de lo que llamamos análisis exploratorio de datos. En el contexto de la exploración, lo importante es trabajar en forma rápida, probando una u otra técnica de visuzalización y refinando nuestros resultados hasta hallar patrones interesantes, o sacarnos dudas acerca de los datos. No necesitamos ponerle título a las visualizaciones, porque ya sabemos de que tratan (¡acabamos de escribirlas!). No nos preocupa que los nombres de los ejes indiquen en forma clara la variable representan, porque ya lo sabemos de antemano.
Pero cuando queremos guardar un gráfico para compartir con otros, sea publicándola en un paper, o enviándola por mail a un amigo, necesitamos tener más cuidado. Hemos pasado del ámbito de la exploración al de la comunicación. Ahora si debe preocuparnos la claridad, porque no sabemos el grado de familiaridad que tiene con los datos la eventual audiencia.
Si bien la comunicación clara es un arte cuyas reglas dependen del contexto, y además cada quien tiene su estilo, podemos decretar al menos tres elementos que no deberían faltar en un gráfico destinado a comunicar algo a los demás:
- Un título descriptivo, pero breve
- Etiquetas claras (no ambiguas) en los ejes
- Nombres descriptivos en las leyendas
y ya que estamos, dos opcionales:
- Un subtítulo donde poner detalles importantes que no entran en un título breve
- Una nota al pie con infromación adicional: fuente de los datos, cita académica, advertencias, etc.
Con ggplot() podemos encargarnos de todo dentro de una sola función, labs() (por labels, etiquetas)
Tomemos un gráfico de los que hicimos antes para pulirlo un poco y que sirva de ejemplo. El original:
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total, fill = TIPO_PRESTACION)) +
coord_flip()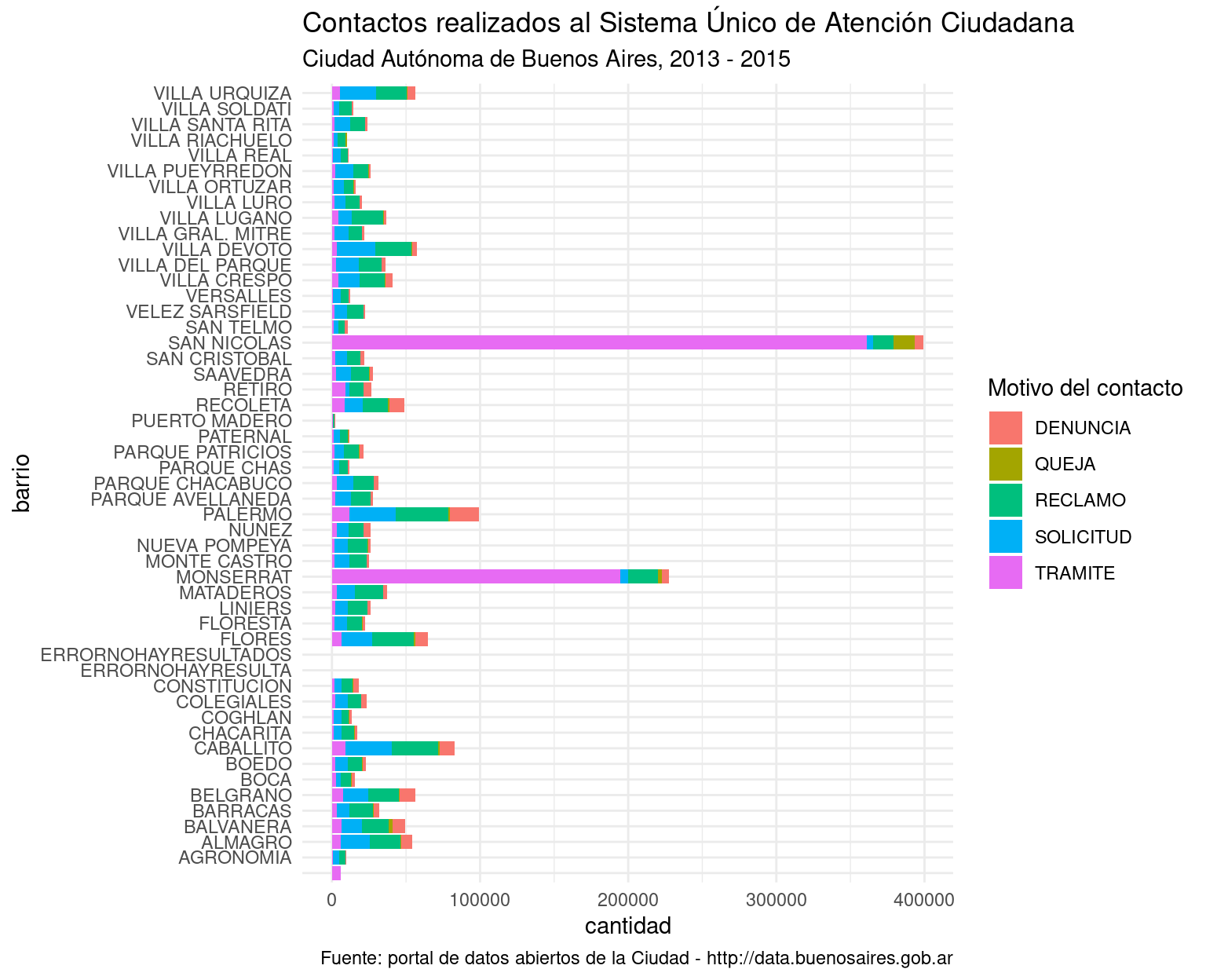
versus la versión pulida usando labs():
ggplot(atencion_ciudadano) +
geom_bar(aes(x = BARRIO, weight = total, fill = TIPO_PRESTACION)) +
coord_flip() +
labs(title = "Contactos realizados al Sistema Único de Atención Ciudadana",
subtitle = "Ciudad Autónoma de Buenos Aires, 2013 - 2015",
caption = "Fuente: portal de datos abiertos de la Ciudad - http://data.buenosaires.gob.ar",
x = "barrio",
y = "cantidad",
fill = "Motivo del contacto")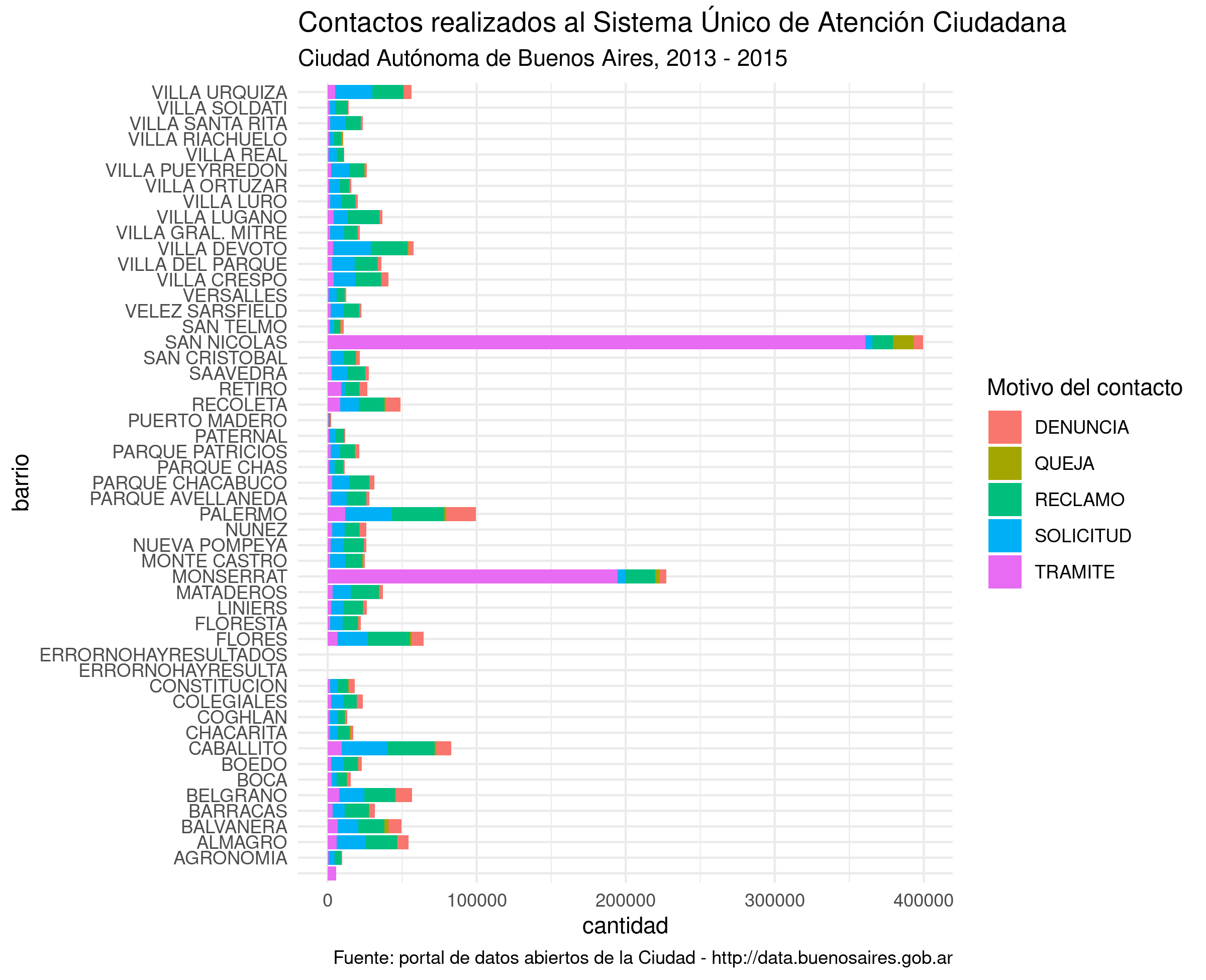
Ahora si, a compartir.
4.7 Otras visualizaciones
Por supuesto, las opciones que hemos repasado son apenas una fracción de la enorme variedad de técnicas de visualización que existen. Para empezar, nos falta hablar de los mapas, una categoría tan importante que tiene un capítulo completo dedicado más adelante.
Y aún quedan tantas por discutir, que sería imposible hacerles justicia en un libro introductorio. Con nombres tan variopintos como waffle charts, violin plots, o tree maps, existen quizás un centenar o más de métodos bien documentados para explorar información en forma visual.
El sitio web from Data to Viz (https://www.data-to-viz.com/) es un recurso excelente para investigar opciones. Contiene un compendio visual e interactivo de técnicas de visualización con sus nombres y características generales. También explica a que familia corresponde cada una, y para qué suele usarse (mostrar relaciones, distribuciones, cambio a través del tiempo, etc).
Figura 4.1: from Data to Viz - www.data-to-viz.com/
Y lo más interesante: Para todas y cada una de las visualizaciones se incluye el código en R que permite reproducirlas. A partir de allí sólo es cuestión de adaptar los ejemplos a nuestros datos para realizar de forma fácil la visualización que nos interesa.