La irrupción de computadoras llenas de sensores que viajan el bolsillo de cada ciudadano -nuestros celulares- ha sido de sobra aprovechada por Google. Si no nos tomamos la molestia de inhabilitar funciones de localización activas de fábrica, todos los usuarios de celulares Android reportamos a Google nuestra posición, en forma constante. Y los usuarios de iPhones también, cuando usan servicios de la compañía en sus teléfonos.
A esta altura, ya todos sabemos que Google es una compañía bastante creepy. A cambio de unos cuantos servicios que hemos pasado a considerar imprescindibles, “sólo” quieren conocimiento completo de quiénes somos, qué hacemos, qué deseamos, y dónde estamos. Lo que Google hace con la cuantiosa información que acumula de sus miles de millones de usuarios es un misterio, al menos en cuanto a los detalles y al alcance de sus análisis.
Por eso es interesante hacer algunos ejercicios por nuestra cuenta, visualizando los datos de localización que Google ha recopilado sobre nosotros. Interroguemos a la data con una pregunta general en mente: ¿Qué puede inferir Google acerca de mi si sabe donde estoy?
Descargando nuestra información de ubicación
El primer paso es acceder a la información que Google dispone de nosotros. Entrando en https://takeout.google.com/settings/takeout podemos descargar archivos comprimidos con la información personal que Google mantiene en sus distintos servicios. Para nuestros fines, solo necesitamos los datos de ubicación. De-seleccionamos todas las opciones, y activamos sólo “Location History” / “Historial de Ubicaciones”, en formato JSON:
Google takeout
Cliqueando en “Siguiente” podemos iniciar la descarga.
Preparación de los datos
Una amable persona me ha donado su set de datos de ubicación para que juegue con ellos. Con el archivo de ubicaciones en nuestro poder, el impulso es generar visualizaciones de inmediato… pero como de costumbre, hay que masajear los datos para que queden utilizables.
Primero convertimos el archivo JSON a un dataframe. Lo leemos como objeto de R usando la función fromJSON, disponible en el paquete jsonlite:
library(jsonlite)
raw <- fromJSON('../../../../data/Google/Location History/Location History.json')Generamos un dataframe con pares latitud/longitud más la fecha. Y de paso algunos datos extra, como velocidad, precisión del registro, dirección, altitud, y la actividad que Google supone que estábamos realizando (estar quietos, viajar a pie, en bici, otro vehículo, etc):
library(tidyverse)
library(lubridate)
locs <- raw$locations
locationdf <- data.frame(t=rep(0,nrow(locs)))
# convertimos lat y long a variables numéricas
locationdf$lat <- as.numeric(locs$latitudeE7/1E7)
locationdf$lon <- as.numeric(locs$longitudeE7/1E7)
# Nos llevamos los datos de precisión
locationdf$accuracy <- locs$accuracy
# Y la actividad más probable para cada lectura de posición
act <- map_df(locs$activity,
function(f) {
if(is.null(f[[1]]))
data.frame(activity=NA,confidence=NA,stringsAsFactors=F)
else
data.frame(activity=f[[2]][[1]][[1]][1],
confidence=f[[2]][[1]][[2]][1],stringsAsFactors=F)
})
# Agregar los datos de actividad a nuestro dataframe principal
locationdf$activity <- act$activity
locationdf$confidence <- act$confidence
# Velocity, altitude y heading también
locationdf$velocity <- locs$velocity
locationdf$altitude <- locs$altitude
locationdf$heading <- locs$heading
# Agregar un campo con fecha en calendario gregoriano,
# y campos para día de la semana, mes y año
# El formato de la fecha es POSIX * 1000 (milliseconds) lo pasamos a una escala más útil...
locationdf$date <- as.numeric(locs$timestampMs)/1000
class(locationdf$date) <- 'POSIXct'
locationdf$weekday <- weekdays(as.Date(locationdf$date))
locationdf$month <- months(as.Date(locationdf$date))
locationdf$year <- year(as.Date(locationdf$date))
# En el campo "activity" convertimos valores NA en "UNKNOWN"
locationdf$activity = ifelse(is.na(locationdf$activity), "UNKNOWN", locationdf$activity)
# Agregar un indice y ordenarlo en reversa (el registro más reciente al final)
locationdf <- locationdf[rev(rownames(locationdf)),]Primera aproximación a los datos
Para ir conociendo los datos, vamos a empezar con algo básico: Determinar que lapso de tiempo abarcan, y que tipo de “actividades” han sido registradas.
Para que los plots nos queden bonitos, usaremos los themes credos por Bob Rudis, “hrbrthemes”.
#devtools::install_github("hrbrmstr/hrbrthemes")
library(hrbrthemes)Y ahora, un “stacked area chart”, para mostrar la evolución de la cantidad de registros capturados diariamente. Este tipo de visualización funciona bien cuando se quiere mostrar a lo largo del tiempo la contribución que distintas categorías hacen a un total.
# Renombrar activity como actividad, crear campo con mes y año, agrupar por actividad + fecha
locationdf %>%
mutate(fecha = ymd(date(date))) %>%
group_by(activity, fecha) %>%
summarise(total = n()) %>%
arrange(fecha, activity, desc(total)) %>%
ggplot(aes(x=fecha, y=total)) +
geom_area(aes(fill=activity), position="stack") +
scale_x_date() +
ylim(c(0, 1750)) +
labs(y="registros",
title="Historial de ubicaciones de Google",
subtitle="Cantidad de registros por dia y por actividad") +
scale_fill_brewer(palette = "Set3") +
theme_ipsum()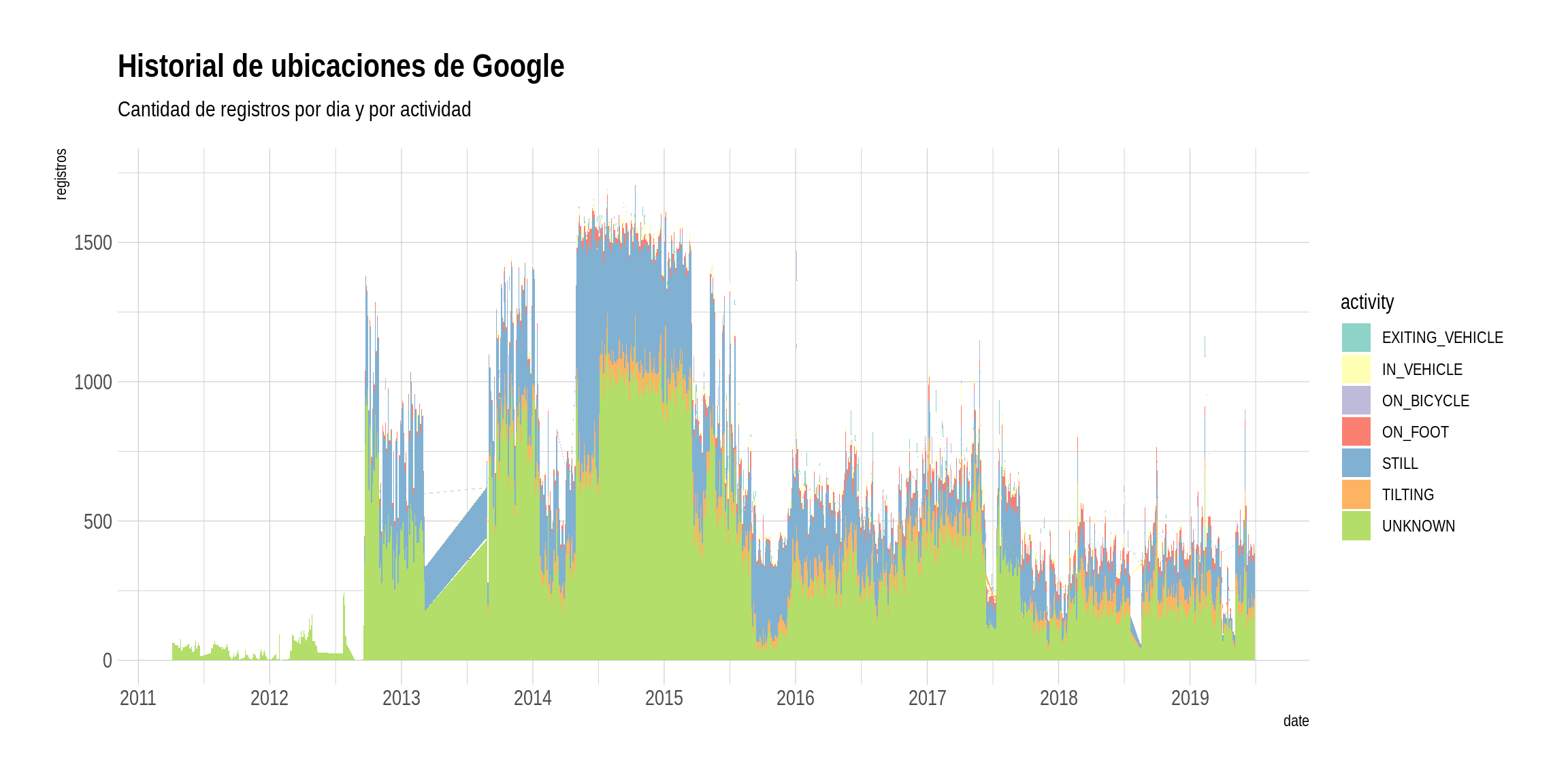
El gráfico indica que tenemos registros desde el 2011 hasta mediados del 2017. Durante los dos primeros años, los registros de ubicación fueron escasos. A fines del 2012 explota la frecuencia diaria de notificaciones a Google de la posición del usuario. Hay valles donde la frecuencia de registros baja notablemente, en 2013, 2014 y 2015. El del 2013 (la pendiente prolija) sin dudas parece resultado de un error u omisiones en la data… quizás Google también pierde datos cada tanto! Desde su apogeo en 2014 y 2015, con unos 1500 registros por día, parece ser que se han apiadado de la batería de nuestros celulares y los envíos de coordenadas a la madre nodriza no son tan constantes como antaño.
En cuanto a las actividades registradas, “unknown” -desconocido- es la categoría más común. Le siguen “still” (o quieto), y mucho más lejos “tilting” (realizando un giro) y “on foot” (caminando). Es decir que para la gran mayoría de las veces que lee nuestra ubicación, Google sabe donde estamos pero no puede determinar de que modo nos movemos. Diría que en la práctica esto es compensado analizando registros de posición en conjunto: si un registro dado es identificado como “on foot” (por ejemplo) por el algoritmo que categoriza la actividad, otros registros donde la dirección y velocidad son más o menos constantes pueden considerarse parte de la misma secuencia de movimiento.
Para visualizar cuantos registros aporta cada categoría en la suma total, intentemos con un “waffle chart”. Los gráficos de waffle son una alternativa a los gráficos de torta, que además de continuar con la nomenclatura gastronómica resultan, al menos en teoría, más fáciles de interpretar que sus primos circulares.
library(waffle)
top5 <- locationdf %>%
filter(activity != "UNKNOWN") %>%
group_by(activity) %>%
tally() %>%
arrange(desc(n)) %>%
slice(1:5)
# 1 cuadradito del waflle = 10000 registros
# De paso, conertimso el dataframe en un vector nombrado como quiere la funcion waffle()
top5 <- structure(top5[[2]] / 10000, names = top5[[1]])
waffle(top5,
rows = 4,
legend_pos = "bottom",
xlab = "1 cuadradito == 10.000 registros",
title = "Top 5 actividades identificadas")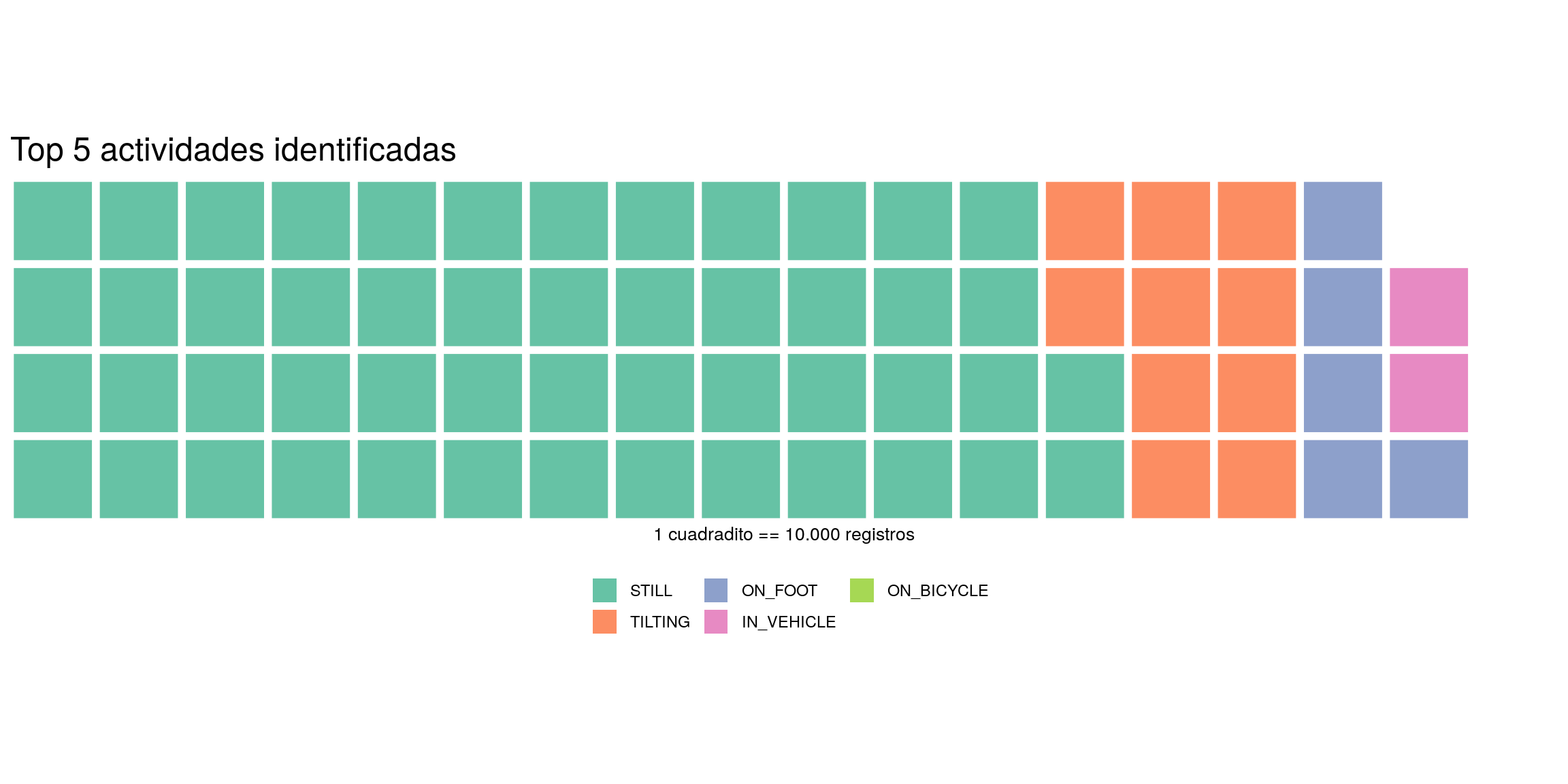
Vemos que, al menos en cuanto a lo que ha podido establecer Google, el usuario es encontrado caminando en forma tres veces más habitual que a bordo de un vehículo. Por otro lado, “still” le gana por goleada a “on foot”, así que esa propensión a caminar es balanceada por cierto sedentarismo. Todo un mal de nuestros días, je. En todo caso las conclusiones deben ser tomadas con pinzas; estamos asumiendo que las actividades no identificadas (“unknown”) se reparten en la misma proporción que las etiquetadas.
Prestando atención a un categoría en particular
Concentrémonos en los registros que encuentran al usuario caminando. Cuál es su día de mayor movimiento a pie?
locationdf %>%
mutate(weekday = ordered(weekday,
levels = c("lunes", "martes", "miércoles", "jueves",
"viernes", "sábado", "domingo"))) %>%
filter(activity == "ON_FOOT") %>%
count(weekday) %>%
mutate(pct=n/sum(n)) %>%
ggplot(aes(weekday, pct)) +
geom_col() +
scale_y_percent() +
labs(x="",
y="Porporción de los registros capturados por Google (%)",
title="Movimiento a pie registrado",
subtitle="según el día de la semana") +
theme_ipsum(grid="Y")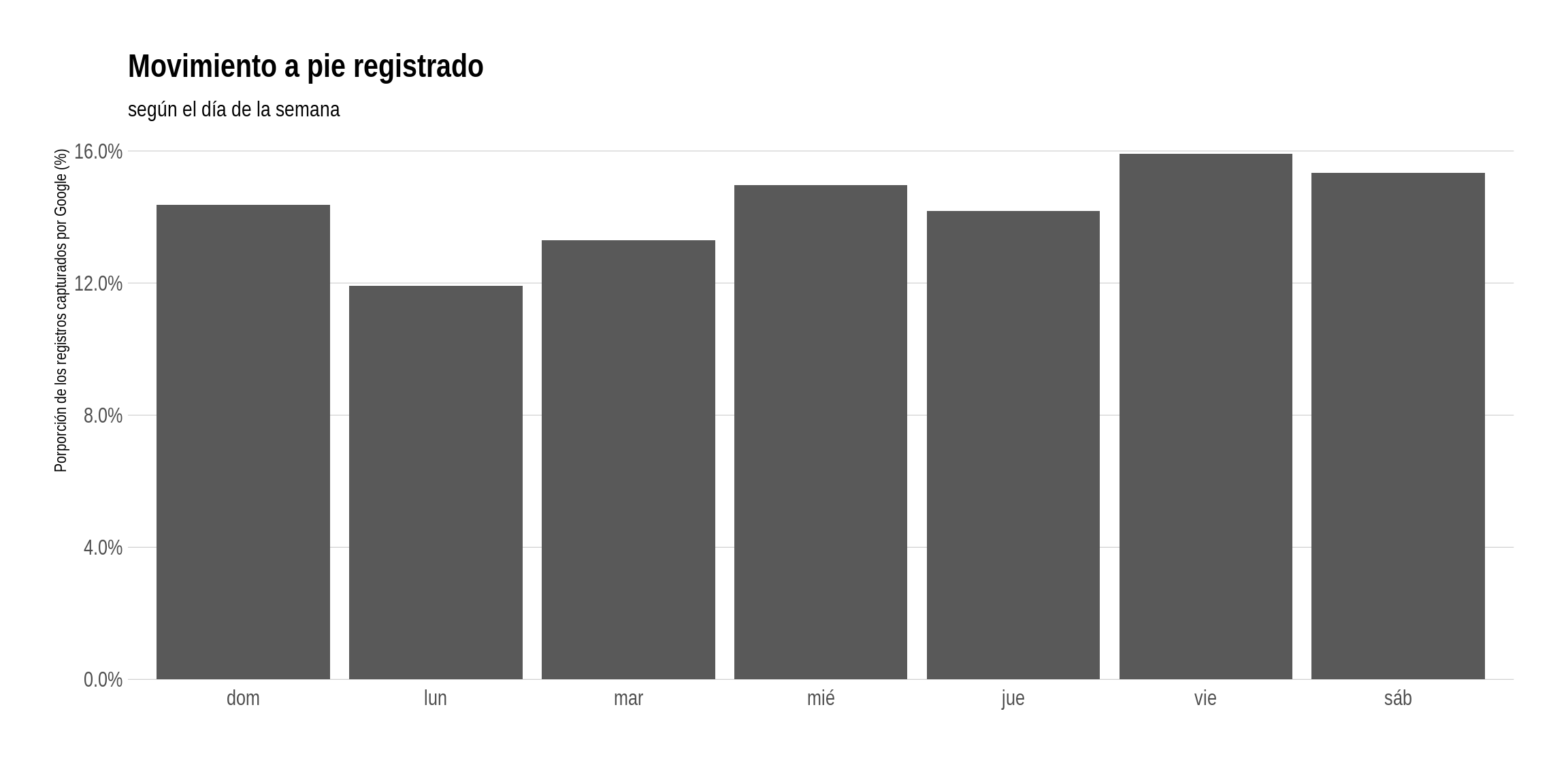
Para nuestro usuario donante, el viernes es el gran día para pasear (quizás de noche?), al igual que el fin de semana. El lunes, en cambio, registra los valores más bajos. Lunes de ánimo caído? Quizás no! Cada vez que visualizamos resúmenes de datos acumulados durante un período largo, es importante verificar que no se no esté escapando algo relacionado con el paso del tiempo. En este caso, la suma total por día de la semana podría estar ocultando diferencias claras entre distintos años. Peguemos una mirada, separando los registros por año:
locationdf %>%
mutate(weekday = ordered(weekday,
levels = c("lunes", "martes", "miércoles", "jueves",
"viernes", "sábado", "domingo"))) %>%
filter(activity == "ON_FOOT") %>%
count(weekday, year) %>%
mutate(pct=n/sum(n)) %>%
ggplot(aes(weekday, pct)) +
geom_col() +
facet_wrap(~year, scales = "free") +
labs(x="",
y="Porporción anual de los registros capturados por Google",
title="Movimiento a pie registrado",
subtitle="según el día de la semana") +
theme_ipsum(grid="Y") +
theme(axis.text.x = element_text(angle = 45, hjust = 1),
axis.text.y=element_blank())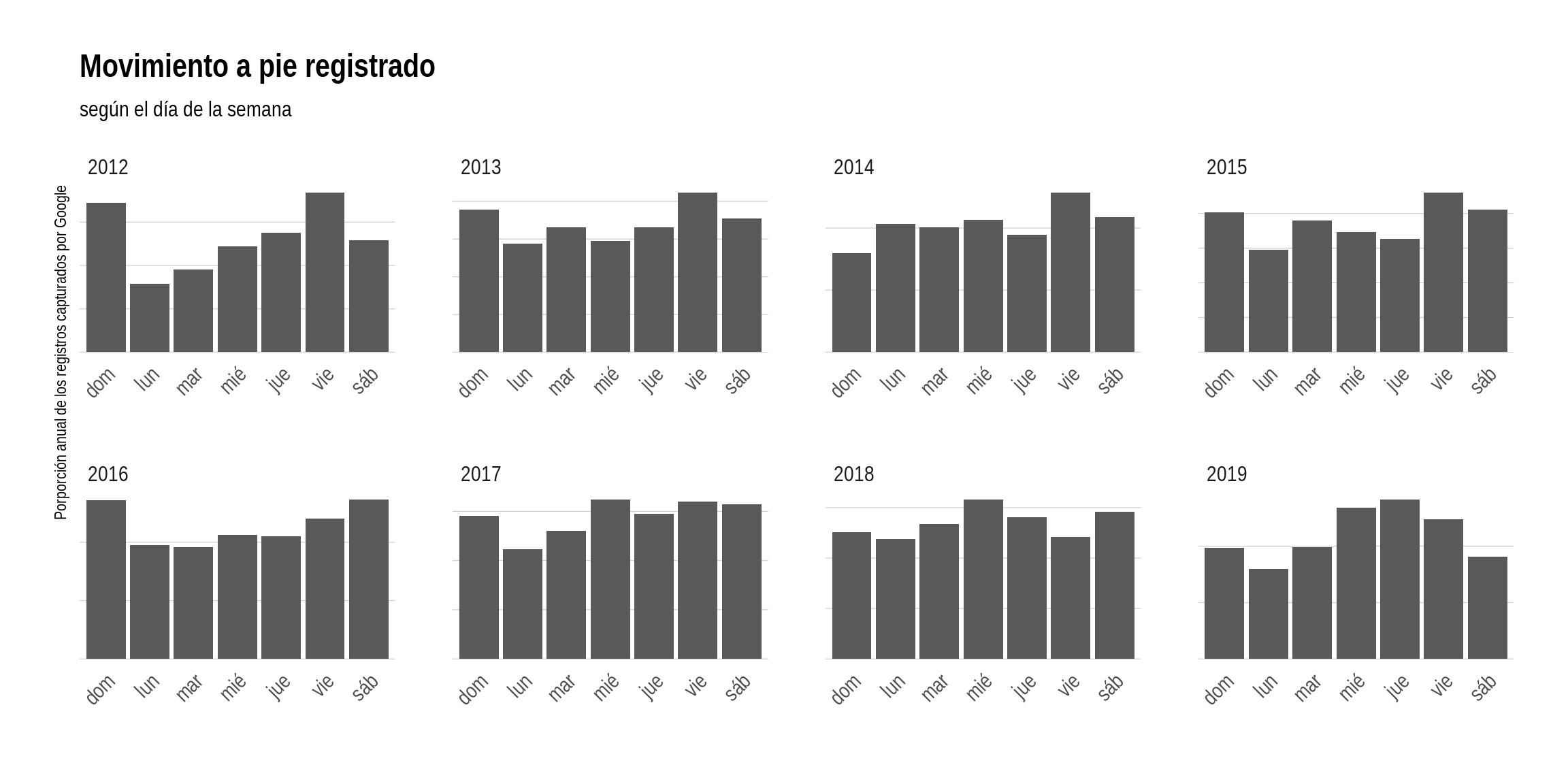
Queda claro que el gráfico anterior resultaba engañoso. Si los datos de Google son confiables, nuestro usuario ha ido variando sus ritmos diarios con los años. En 2012 (y en el 2016 también) su día de paseo era el domingo. En lo que va del 2017, la mayor actividad de caminata se registra los miércoles.
Identificando lugares
Vamos ahora al grano. Al visualizar datos de ubicación, sin duda queremos ver lugares en el mapa! Para empezar, agreguemos un campo a nuestro dataset con la ciudad en la que fue efectuado cada registro. Esto es más complejo de lo que podría pensarse de inmediato, ya que la definición de “qué es” una ciudad varía entre regiones. También es difícil encontrar consenso acerca de las fronteras exactas de muchas de las miles de ciudades que en este mundo hay. Decidir a que ciudad corresponde un set de coordenadas puntual no debería ser muy complicado; pero escribir un algoritmo que lo haga en gran escala para coordenadas en cualquier lugar del globo es un desafío considerable.
En este caso, estoy interesado en seguir los movimientos de un usuario mientras visita por trabajo o turismo distintas ciudades. Por eso no me preocupa saber el nombre de la localidad en la que se encuentre en cada momento, si no el de la ciudad principal de la región. La solución para el problema así definido:
- Tomar una lista con la posición y la población de las ciudades del mundo
- Seleccionar aquellas que cuentan con una población considerable, digamos 100.000 habitantes
- Para cada ubicación registrada por Google, encontrar la ciudad más cercana de nuestra lista
Es una de esas tareas que serían desesperantes para un ser humano, pero triviales par una computadora. Excelente.
En https://opendata.arcgis.com/datasets/6996f03a1b364dbab4008d99380370ed_0.csv se puede descargar una base de datos de acceso libre y gratuito, que incluye (entre otros campos) nombre, código de país, latitud, longitud y población de las principales ciudades del mundo. Justo lo que necesitamos.
cities <- read.csv('/home/havb/data/World_Cities.csv', stringsAsFactors = F) %>%
filter(POP > 100000)Algo a tener en cuenta aquí es la performance del algoritmo que vamos a usar para encontrar la ciudad más cercana. Tenemos más de 1200 ciudades:
nrow(cities)## [1] 1231Y más de 1.300.000 registros de ubicación:
nrow(locationdf)## [1] 1312415Usar un loop “inocente” que compare cada registros contra todas las ciudades para encontrar la más cercana requeriría más de 1600 millones de operaciones. Está bien que la computadora no se cansa, pero el que se cansa es uno de esperar a que termine. Pero no hay nada que temer! Echaremos mano de un algoritmo muy eficiente para éste tipo de búsquedas, K-nearest neighbors o Knn. En el mundo R hay varias implementaciones de knn listas para usar. Vamos a usar la del paquete SearchTrees.
library(SearchTrees)
# Creamos un árbol de búsqueda con las posiciones definidas por las columnas de latitud y longitud
tree <- createTree(cities, columns=c(2,1))
# Funcion para encontrar la ciudad mas cercanas a un punto dado
findMetro <- function(lat, lon, tree, cities) {
return(cities[knnLookup(tree, lat, lon, k=1), c("CITY_NAME", "CNTRY_NAME")])
}
# Encontrar el area metropolitana para cada registro
locationdf <- cbind(locationdf,
map2_df(locationdf$lat, locationdf$lon,
findMetro, tree = tree, cities = cities))Habiendo identificado cada ciudad, vale la pena agregar dos campos más que van a ser útiles para visualizar la data: país, y tiempo de estadía. Para calcular el tiempo de estadía, asignemos un identificador a cada secuencia de registros consecutivos efectuados en la misma ciudad usando “run-lengh encoding” para luego extraer fecha de inicio y final de cada una. Agregar el país es fácil; sólo necesitamos hacer un join contra una tabla de ciudades y naciones.
runs <- rle(locationdf$CITY_NAME)
estadias <- locationdf %>%
mutate(run_id = rep(seq_along(runs$lengths), runs$lengths)) %>%
group_by(CITY_NAME, CNTRY_NAME, run_id) %>%
summarise(date_in = min(date),
date_out = max(date)) %>%
arrange(date_in) %>%
select(-run_id)
estadias## # A tibble: 171 x 4
## # Groups: CITY_NAME, CNTRY_NAME [28]
## CITY_NAME CNTRY_NAME date_in date_out
## <chr> <chr> <dttm> <dttm>
## 1 Buenos Aires Argentina 1301959888.636 1306159287.876
## 2 La Plata Argentina 1306159479.886 1306192359.628
## 3 Buenos Aires Argentina 1306193665.488 1307719425.635
## 4 La Plata Argentina 1307719623.741 1307748874.83
## 5 Buenos Aires Argentina 1307765657.954 1312817838.016
## 6 Salta Argentina 1312828736.928 1312995091.661
## 7 San Miguel De Tucuman Argentina 1312997048.009 1313106833.44
## 8 Buenos Aires Argentina 1313113824.791 1317501265.995
## 9 La Plata Argentina 1317827208.834 1317830169.106
## 10 Buenos Aires Argentina 1317831680.811 1317831887.856
## # ... with 161 more rowsCon la data prolija, es fácil hacer un ranking de tiempo pasado en cada ciudad…:
ranking <- estadias %>%
mutate(semanas = difftime(date_out,
date_in,
units = "weeks")) %>%
group_by(CITY_NAME, CNTRY_NAME) %>%
summarise(total_semanas = round(sum(semanas), 1)) %>%
arrange(desc(total_semanas))
ranking## # A tibble: 28 x 3
## # Groups: CITY_NAME [28]
## CITY_NAME CNTRY_NAME total_semanas
## <chr> <chr> <time>
## 1 Buenos Aires Argentina 185.5
## 2 Boston United States 83.3
## 3 New York United States 4
## 4 Cordoba Argentina 0.9
## 5 La Plata Argentina 0.9
## 6 Frankfurt Germany 0.7
## 7 Rosario Argentina 0.7
## 8 Reykjavik Iceland 0.6
## 9 Birmingham United Kingdom 0.5
## 10 Washington D.C. United States 0.5
## # ... with 18 more rows… y un mapa de países visitados y duración total de estadías:
library(rworldmap)
# Preparar la data
toMap <- joinCountryData2Map(ungroup(ranking),
joinCode = "NAME",
nameJoinColumn = "CNTRY_NAME")## 28 codes from your data successfully matched countries in the map
## 0 codes from your data failed to match with a country code in the map
## 233 codes from the map weren't represented in your data# A mapear!
library(RColorBrewer)
mapCountryData(toMap,
nameColumnToPlot = "total_semanas",
catMethod = "pretty",
colourPalette = brewer.pal(5, "YlGn"),
oceanCol= "lightblue",
missingCountryCol= "grey40",
mapTitle= "Estadía total (semanas)")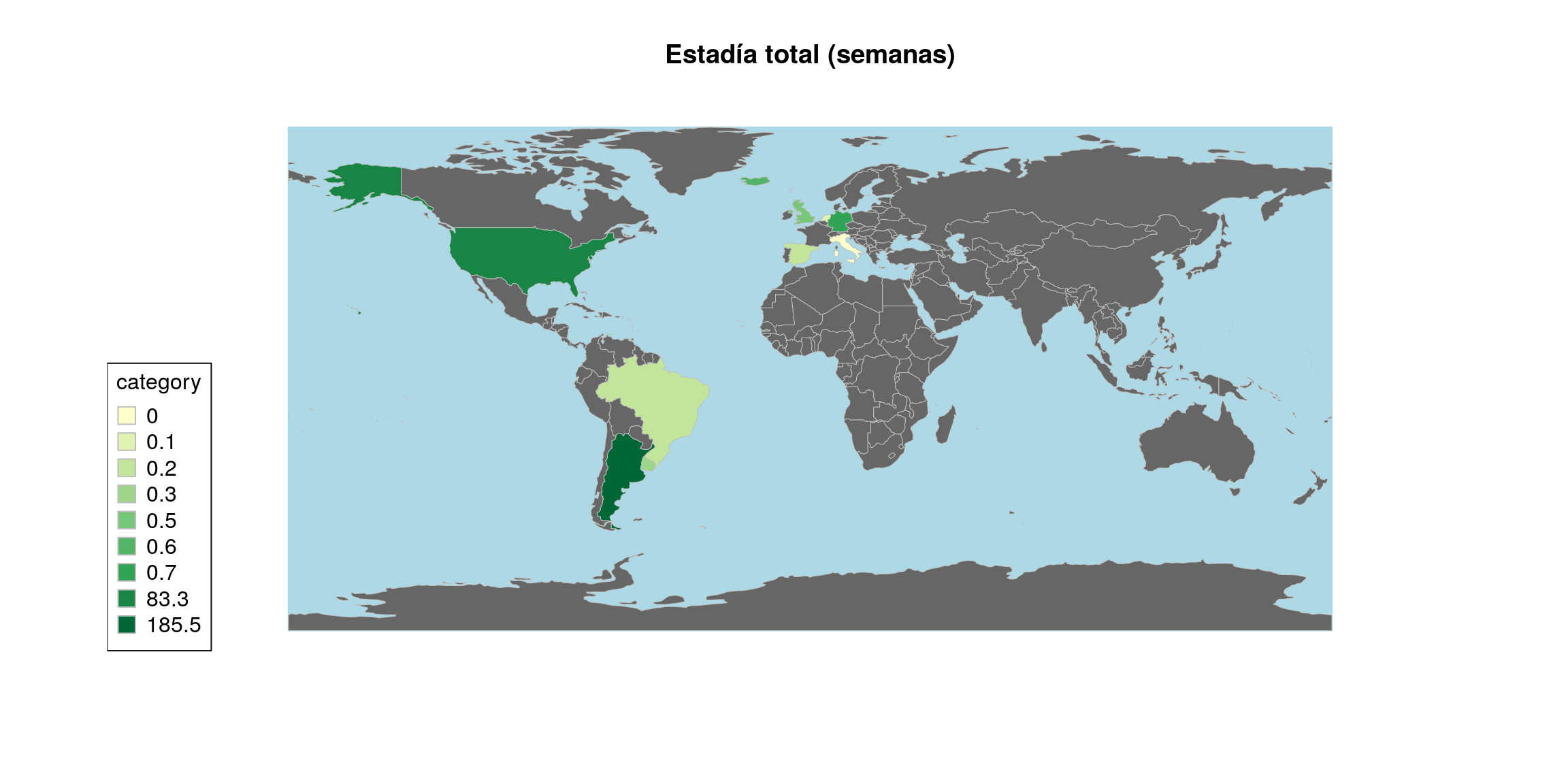
Por último, tracemos una línea de tiempo que siga el derrotero de nuestro usuario. Es fácil detectar cuando se muda:
library(timeline)
estadias <- estadias %>%
mutate(tipo = ifelse(difftime(date_out, date_in, units = "weeks") >= 3,
"residencia",
"visita")) %>%
as.data.frame
timeline(filter(estadias, tipo == "residencia"),
filter(estadias, tipo == "visita" )[c(1,3)],
text.size = 0, group.col = "tipo",
event.label.method = 2, event.text.size = 2) +
theme_ipsum() +
scale_fill_ipsum(name = "Residencia") +
labs(x="año",
y="",
title="Ciudad de residencia y ciudades visitadas",
subtitle = "Inferencia según registros de ubicación de Google",
caption = "cada punto representa una visita") +
theme(axis.text.y=element_blank())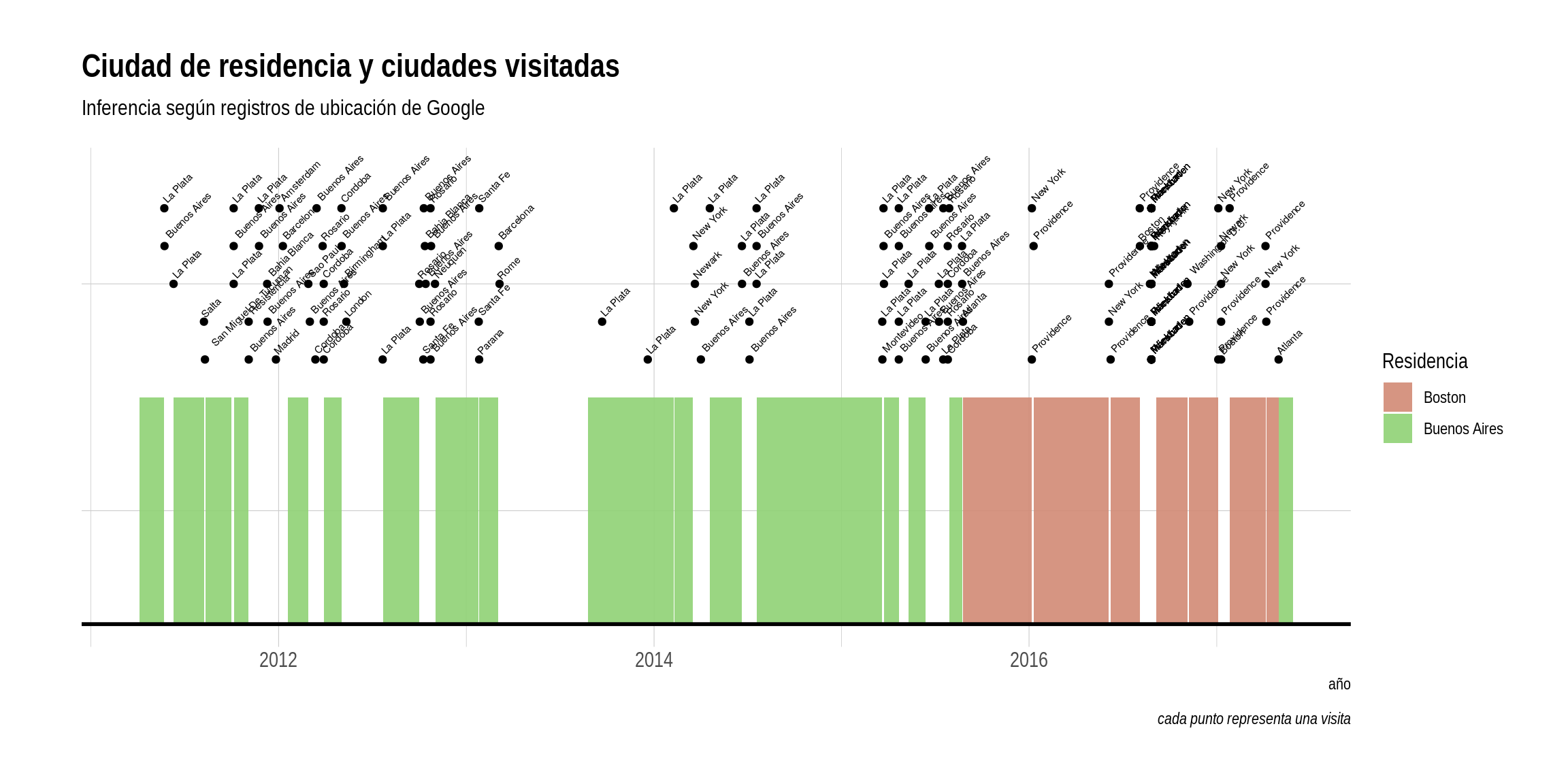
Hay algunos problemas con esta visualización: La nube de puntos que representa ciudades visitadas es difícil de leer, e incluye en algunos casos la ciudad donde se supone que el usuario reside. Esto último se debe a que definimos una “visita” como cualquier estadía menor a un mes. Cuando el usuario pasa unas pocas semanas en su casa debido a viajes frecuentes, ese periodo aparece como si hubiera estado de visita en nuestro gráfico. De todas formas, para un puñado de líneas de código los resultados son interesantes, y de hecho permiten hacerse una buena idea de los desplazamientos del usuario. Y si lo vemos nosotros con tanta facilidad, desde ya que Google lo sabe desde hace tiempo.
En la parte II, vamos a hacer zoom a nivel ciudad para perseguir más a nuestro pobre usuario, tratando de identificar donde vive, donde trabaja y como cambia su conducta según el día de la semana. Pero todo con benévolas intenciones, por supuesto.