Hace unos meses, durante la Smart City Expo en Buenos Aires se organizó un Datatón bajo el título de “Un día en las ciudades a través de sus datos”. El evento fue organizado por los equipos de datos abiertos de la Nación, y la Ciudad y Provincia1 de Buenos Aires.
Con motivo del evento se hicieron públicos varios datasets con información urbana. Entre ellos, una muestra de viajes en taxi solicitados mediante la app BA TAXI.
Information is beautiful
Cuando vi pasar el dataset, lo primero que se me ocurrió fue visualizar todos los viajes a la vez, al estilo del mapa que hizo el MIT Senseable City Lab para los taxis de Nueva York:
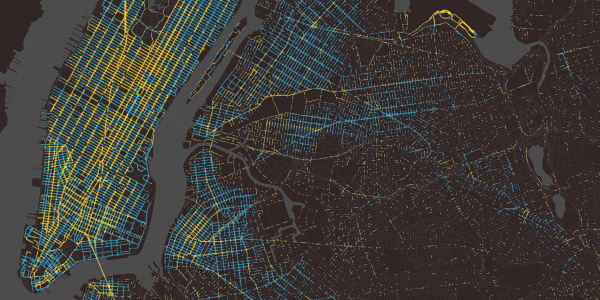
hubcab.org
En resumidas cuentas, obtuve lo que buscaba, y algo más. En un ejemplo de los patrones que son difíciles de detectar en una lista de números, pero resultan evidentes una vez visualizados, en mi mapa relucen rastros de lo que a los porteños nos gusta llamar “la mafia de los taxis”.
Pero vayamos por partes.
Haciendo el mapa
Los ingredientes necesarios son (además de R u otro entorno de programación analítica),
- El dataset de BA Taxi, disponible aquí
- Un archivo georeferenciado con las calles de Buenos Aires, disponible en el portal de datos abiertos de la Ciudad como shapefile, o aquí en el mucho más práctico formato geojson. Yo voy a usar éste último.
Ahora, la receta.
I. Cargamos la data:
library(tidyverse)
library(rgdal)
library(hrbrthemes)
taxis <- read.csv('../data/bataxi.csv', sep = ";", stringsAsFactors = F)
calles <- fortify(readOGR('../data/calles_CABA.geojson'))## OGR data source with driver: GeoJSON
## Source: "../data/calles_CABA.geojson", layer: "calles_CABA"
## with 30037 features
## It has 1 fields# Leve limpieza: pasamos las coordenadas a formato numérico
taxis <- taxis %>%
mutate(origen_viaje_x = as.numeric(gsub(",", ".", origen_viaje_x)),
origen_viaje_y = as.numeric(gsub(",", ".", origen_viaje_y)),
destino_viaje_x = as.numeric(gsub(",", ".", destino_viaje_x)),
destino_viaje_y = as.numeric(gsub(",", ".", destino_viaje_y)))- Echamos un vistazo rápido a las coordenadas de los viajes:
ggplot(data = taxis) +
geom_point(aes(x = origen_viaje_x, y = origen_viaje_y),
size = 0.06,
alpha = .5) +
coord_map()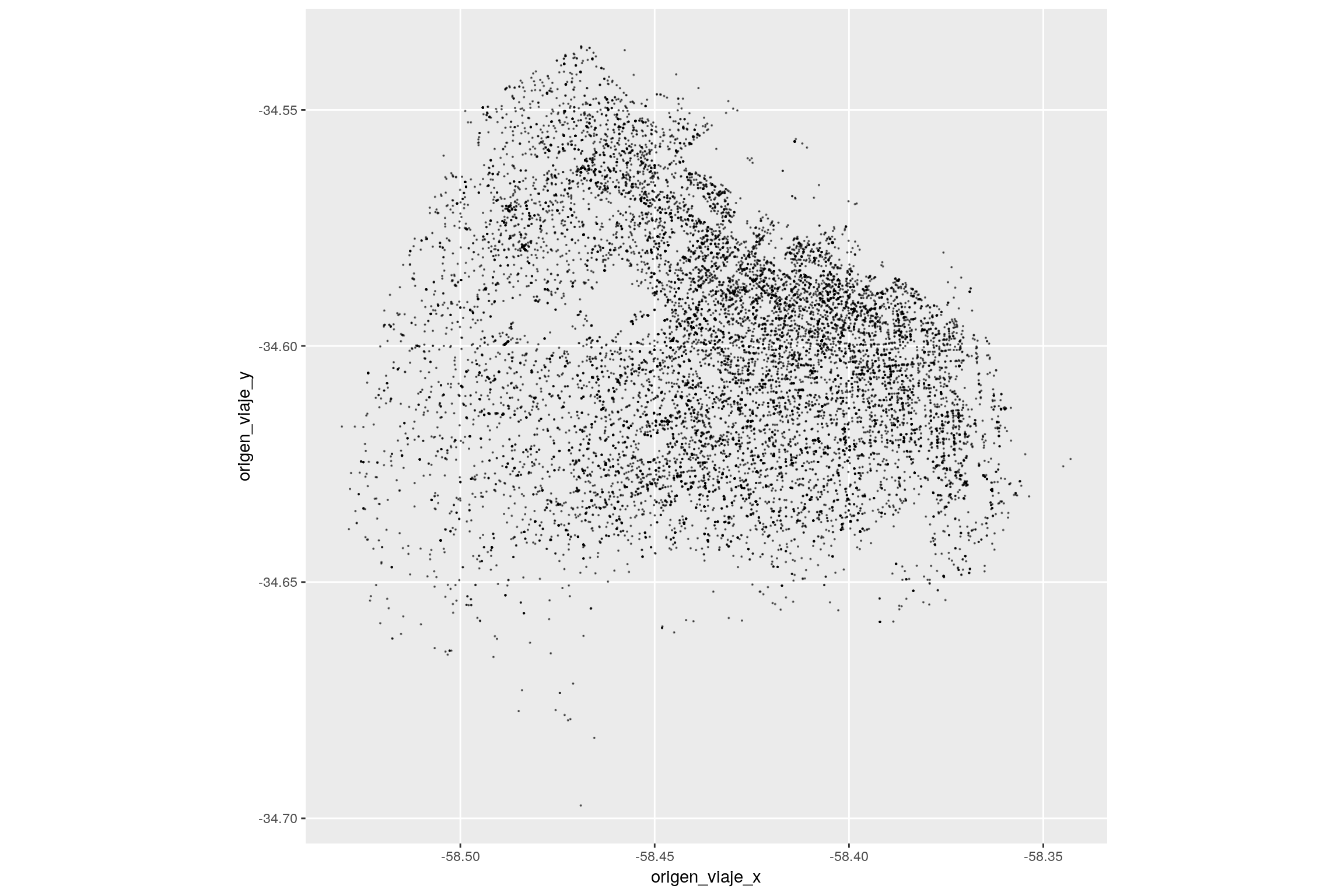
La data es lo suficientemente densa como para que se entrevea la estructura vial de la ciudad. Excelente! Ahora vamos a refinar la visualización.
- Separamos las coordenadas en “orígenes” (donde el taxi levantó pasajeros) y destinos, los lugares de llegada.
taxis_origenes <- taxis %>%
group_by(origen_viaje_x, origen_viaje_y) %>%
summarise(n = n(),
tipo = "origen") %>%
rename(lon = origen_viaje_x,
lat = origen_viaje_y)
taxis_destinos <- taxis %>%
group_by(destino_viaje_x, destino_viaje_y) %>%
summarise(n = n(),
tipo = "destino") %>%
rename(lon = destino_viaje_x,
lat = destino_viaje_y)- Creamos un “template” para el mapa que use fondo negro, que siempre queda flashero con info proyectada encima en colores brillantes. También definimos color y tamaño de título y subtítulo, y vamos a por un look mínimo retirando todos los componentes posibles: chau grilla de fondo, chau leyendas en los ejes, etc.
theme_ipsum_map_dark <- function(base_size = 24, title_size = 60,
subtitle_size = 48, caption_size = 40) {
color.background = "black"
color.title = "gray80"
color.axis.title = "gray80"
theme_ipsum(base_size=base_size) +
theme(rect=element_rect(fill=color.background, color=color.background)) +
theme(plot.background=element_rect(fill=color.background
, color=color.background)) +
theme(panel.border=element_rect(color=color.background, fill = NA)) +
theme(panel.background = element_rect(fill = color.background)) +
theme(panel.grid.major=element_blank()) +
theme(panel.grid.minor=element_blank()) +
theme(axis.ticks=element_blank()) +
theme(legend.background = element_rect(fill=color.background)) +
theme(legend.text = element_text(colour=color.axis.title)) +
theme(legend.title = element_blank(), legend.position="top",
legend.direction="horizontal") +
theme(legend.key.width=unit(1, "cm"), legend.key.height=unit(0.25, "cm"),
legend.spacing = unit(-0.5,"cm")) +
theme(plot.title=element_text(colour=color.title, size = title_size)) +
theme(plot.subtitle=element_text(colour=color.title, size = subtitle_size)) +
theme(plot.caption=element_text(colour=color.title, size = caption_size)) +
theme(axis.text.x=element_blank()) +
theme(axis.text.y=element_blank()) +
theme(axis.title.y=element_blank()) +
theme(axis.title.x=element_blank()) +
theme(strip.background = element_rect(fill=color.background,
color=color.background),
strip.text = element_text(colour=color.axis.title))
}V. Ya casi estamos. Definimos un rango de transparencia, y de tamaño de los puntos que vamos a mapear. La idea es que en las coordenadas desde donde salen o llegan múltiples viajes sean representadas con puntos más grandes y brillantes. Yo elegí los parámetros en base a prueba y error, ajustando hasta que me gustaron los resultados:
alpha_range = c(0.1, 0.8)
size_range = c(0.2, 0.4)- Todo listo para generar el mapa. Allá vamos!
ggplot() +
geom_polygon(data = calles,
aes(x = long, y = lat, group = group),
color = "grey10", fill = NA) +
geom_point(data = taxis_origenes,
aes(x = lon,
y = lat,
alpha = n,
size = n),
color = "aquamarine") +
geom_point(data = taxis_destinos,
aes(x = lon,
y = lat,
alpha = n,
size = n),
color = "indianred1") +
scale_alpha_continuous(range = alpha_range,
trans = "log",
limits = range(taxis_origenes$n)) +
scale_size_continuous(range = size_range,
trans = "log",
limits = range(taxis_origenes$n)) +
theme_ipsum_map_dark(base_size = 12, title_size = 18,
subtitle_size = 12, caption_size = 10) +
coord_map(xlim = range(taxis_origenes$lon),
ylim = range(taxis_origenes$lat)) +
theme(legend.position="none") +
labs(title="Taxis en Buenos Aires: origen y destino de viajes",
subtitle = "Mayo - agosto 2017",
caption = "fuente: dataset BA Taxi - Datatón Smart City Expo Buenos Aires") 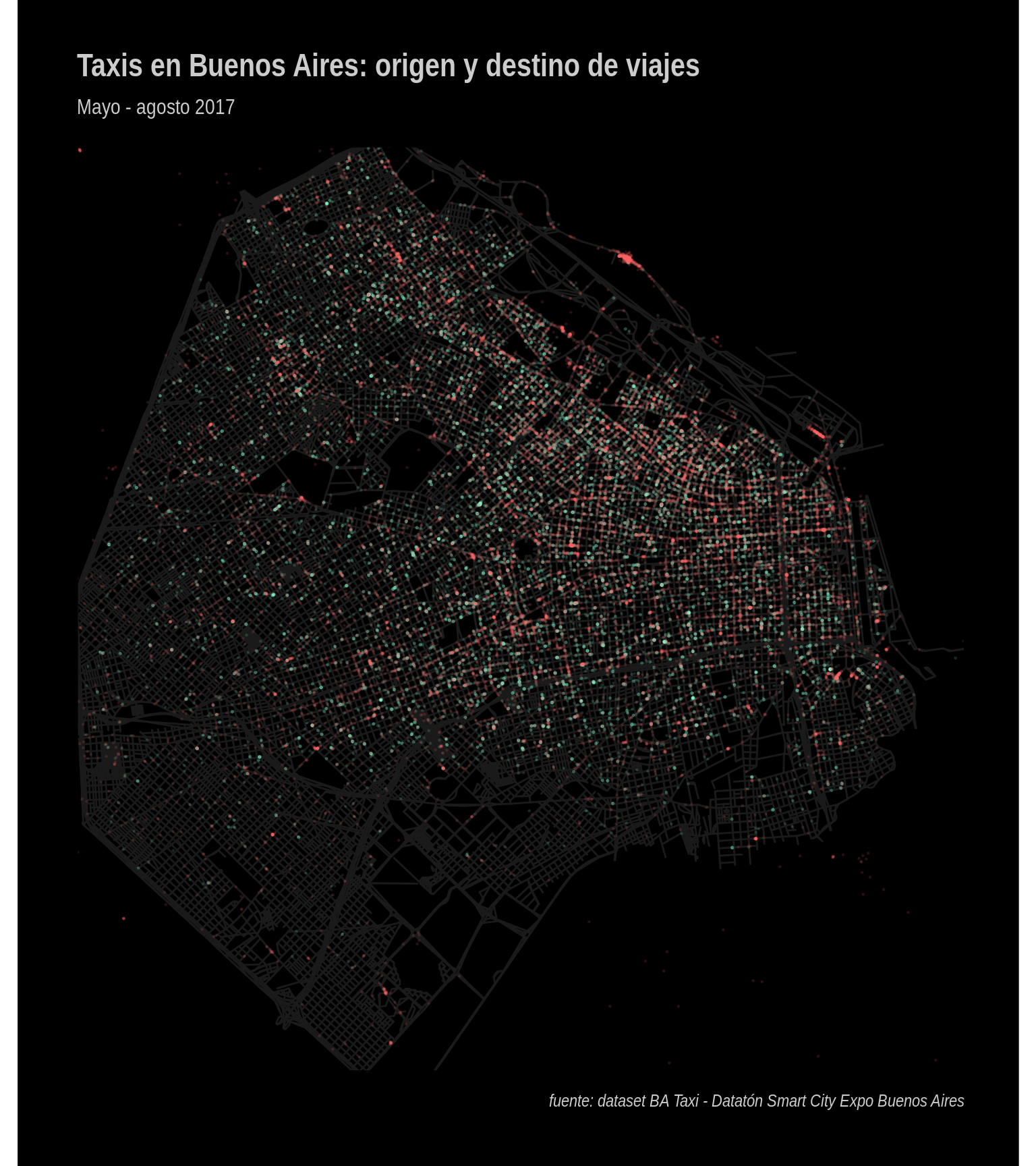
Qué curioso
He aquí la sorpresa. Al norte de la Ciudad, junto al río, aparece una notable aglomeración de taxis bajando pasajeros, pero casi ningún viaje se origina allí. Algo similar, en menor escala, ocurre en la esquina noreste de la Ciudad, cerca del puerto.
Los que tenemos nuestra obsesión por temas de transporte enseguida reconocemos los lugares. Son el aeropuerto de la Ciudad (Aeroparque) y la principal estación de buses de larga distancia (Retiro).
Podemos hacer de forma muy fácil un “zoom in” para verificarlo, usando el paquete ggmaps, que permite descargar desde Google Maps un mapa de cualquier lugar nombrado.
Invoquemos un mapa de “Aeroparque Buenos Aires”, con nuestra data superpuesta:
library(ggmap)qmap("Aeroparque Buenos Aires", zoom = 14, color = "bw", scale = 2) +
geom_point(data = taxis_origenes,
aes(x = lon,
y = lat),
alpha = 0.5,
color = "darkgreen") +
geom_point(data = taxis_destinos,
aes(x = lon,
y = lat),
alpha = 0.5,
color = "indianred1")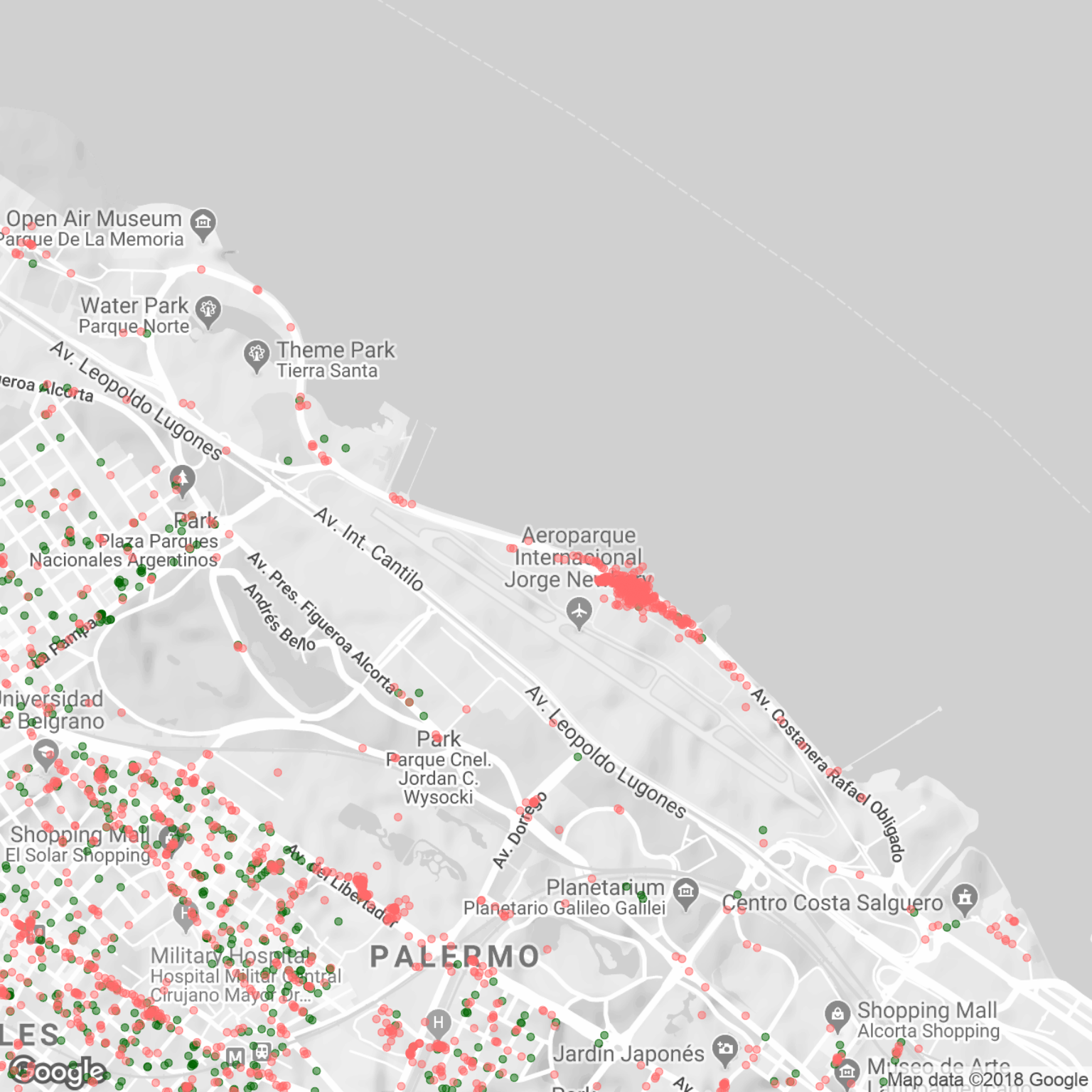
Confirmado, el “misterioso” aglutinamiento de llegadas sin salidas ocurre en Aeroparque.
Ahora pidámosle a Google un mapa de “Estación de buses Retiro”:
qmap("Estación de buses Retiro, Buenos Aires", zoom = 15, color = "bw", scale = 2) +
geom_point(data = taxis_origenes,
aes(x = lon,
y = lat),
alpha = 0.5,
color = "darkgreen") +
geom_point(data = taxis_destinos,
aes(x = lon,
y = lat),
alpha = 0.5,
color = "indianred1")
Es la estación nomás!
Vamos a la explicación. Por si alguno no lo sabía, es vox populi que en Aeroparque y Retiro operan grupos de taxistas confabulados que toman control del área para su uso exclusivo. Quienes pagan por el privilegio, pueden trabajar allí. Los taxistas que no forman parte del negocio e intentan llevarse pasajeros son amenazados o sometidos a violencia para dejar claro que la regla es férrea. Debido a la virtual ausencia de viajes vía BA Taxi que parten desde allí, podemos asumir que los taxistas que trabajan con la app ignoran (por su propio bien!) a los pasajeros que los convocan desde los territorios calientes. La abundancia de puntos rojos demuestra que los choferes de BA Taxi visitan seguido los sitios, dejando pasajeros, pero no se atreven a ir a buscarlos allí.
Dicho esto, algunos puntitos verdes que asoman en ambos sitios sugieren el accionar de taxistas osados -o muy distraídos- que se han llevado pasajeros en las narices de la mafia.
Cuantificando el efecto de la mafia de los taxis
Podemos notar a a simple vista la presencia de territorios vedados. Pero cómo podemos encontrarlos analíticamente? Se puede definir un algoritmo que los detecte?
Claro que sí. Hay muchas maneras de aproximarse a una solución, pero una fácil de explicar es así:
- Dividimos la ciudad con una grilla que divida el espacio en áreas (celdas) iguales.
- En cada celda, medimos la proporción de viajes que llegan vs.. los que se originan allí
- Tomamos la distribución de tasas origen/destino e identificamos los casos anómalos, en particular los que ocurren en áreas de actividad intensa.
Dividimos la ciudad con una grilla que particione el espacio en áreas (celdas) iguales
Usamos el excelente paquete sf, que ofrece una función para proyectar una grilla sobre la extensión de un set de datos georeferenciados.
Para ello juntamos las salidas y llegadas que identificamos antes en un sólo dataset, y lo transformamos en un objeto espacial.
library(sf)
geo_data <- taxis_destinos %>%
bind_rows(taxis_origenes) %>%
st_as_sf(coords = c("lon", "lat"), crs = 4326)
plot(geo_data["tipo"], col = c("aquamarine", "indianred1"),
key.pos = NULL, main = "salidas en verde, llegadas en rojo")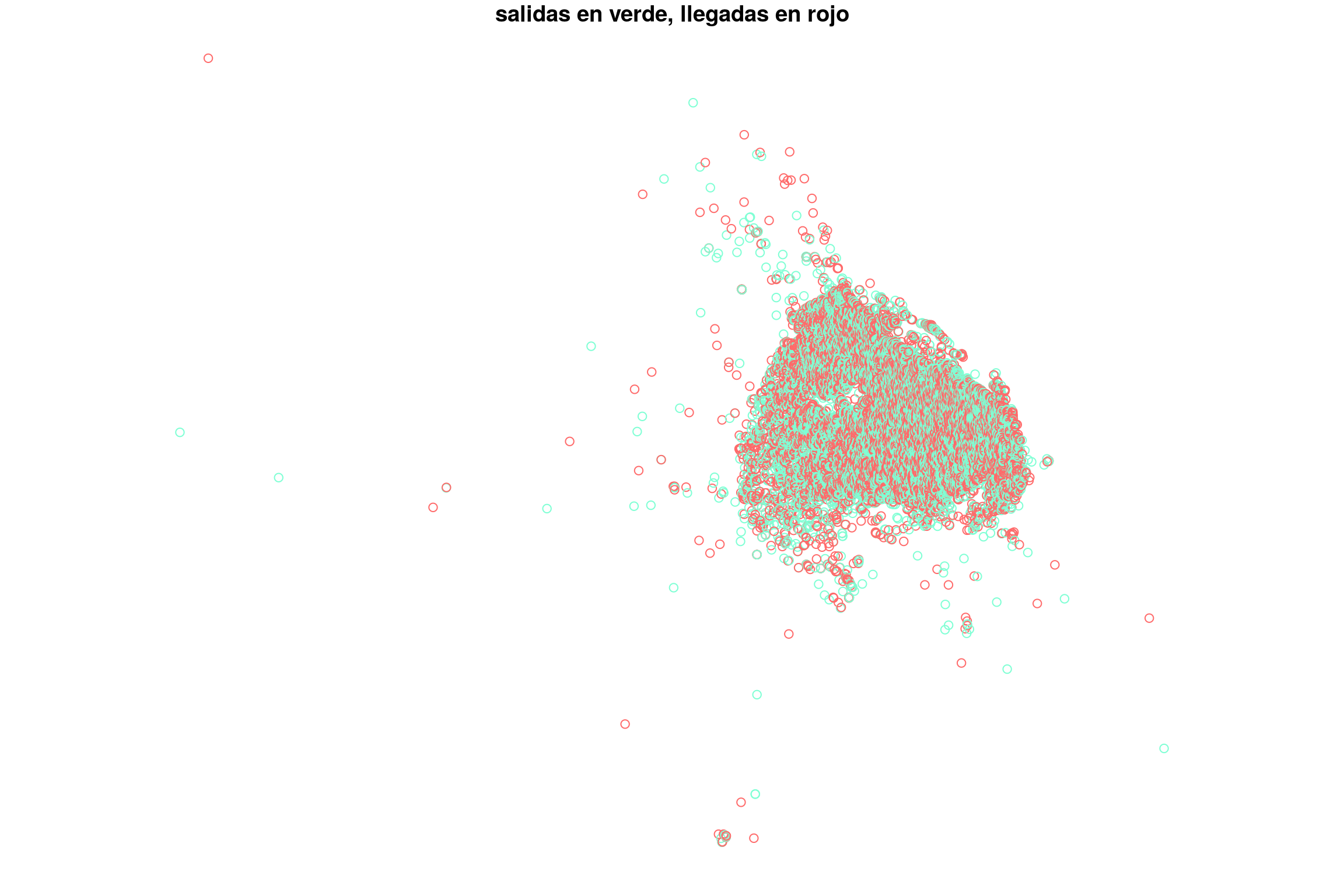
Se evidencia un pequeño problema: Existen varios viajes que terminan fuera de los límites de la Ciudad. Sólo nos interesan viajes dentro de sus fronteras, ya que fuera de ellas es natural que existan más llegadas que salidas, asumiendo que los pasajeros que hacen el camino inverso tenderán a utilizar servicios de taxi locales que no son registrados en el dataset de BA Taxi.
No hay problema. Leemos el archivo que contiene los límites de los barrios de Buenos Aires (también cortesía de Buenos Aires Data) y lo “disolvemos” para que nos quede un sólo polígono que representa la superficie de la ciudad.
limites_CABA <- st_read('../data/barrios/barrios_badata.shp') %>%
st_transform(4326) %>%
mutate(ciudad = "CABA") %>%
group_by(ciudad) %>%
summarise()## Reading layer `barrios_badata' from data source `/home/havb/Dropbox/blog/content/data/barrios/barrios_badata.shp' using driver `ESRI Shapefile'
## Simple feature collection with 48 features and 4 fields
## geometry type: POLYGON
## dimension: XY
## bbox: xmin: 93743.42 ymin: 91566.42 xmax: 111752 ymax: 111285.1
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=-34.6297166 +lon_0=-58.4627 +k=0.9999980000000001 +x_0=100000 +y_0=100000 +ellps=intl +units=m +no_defsplot(limites_CABA)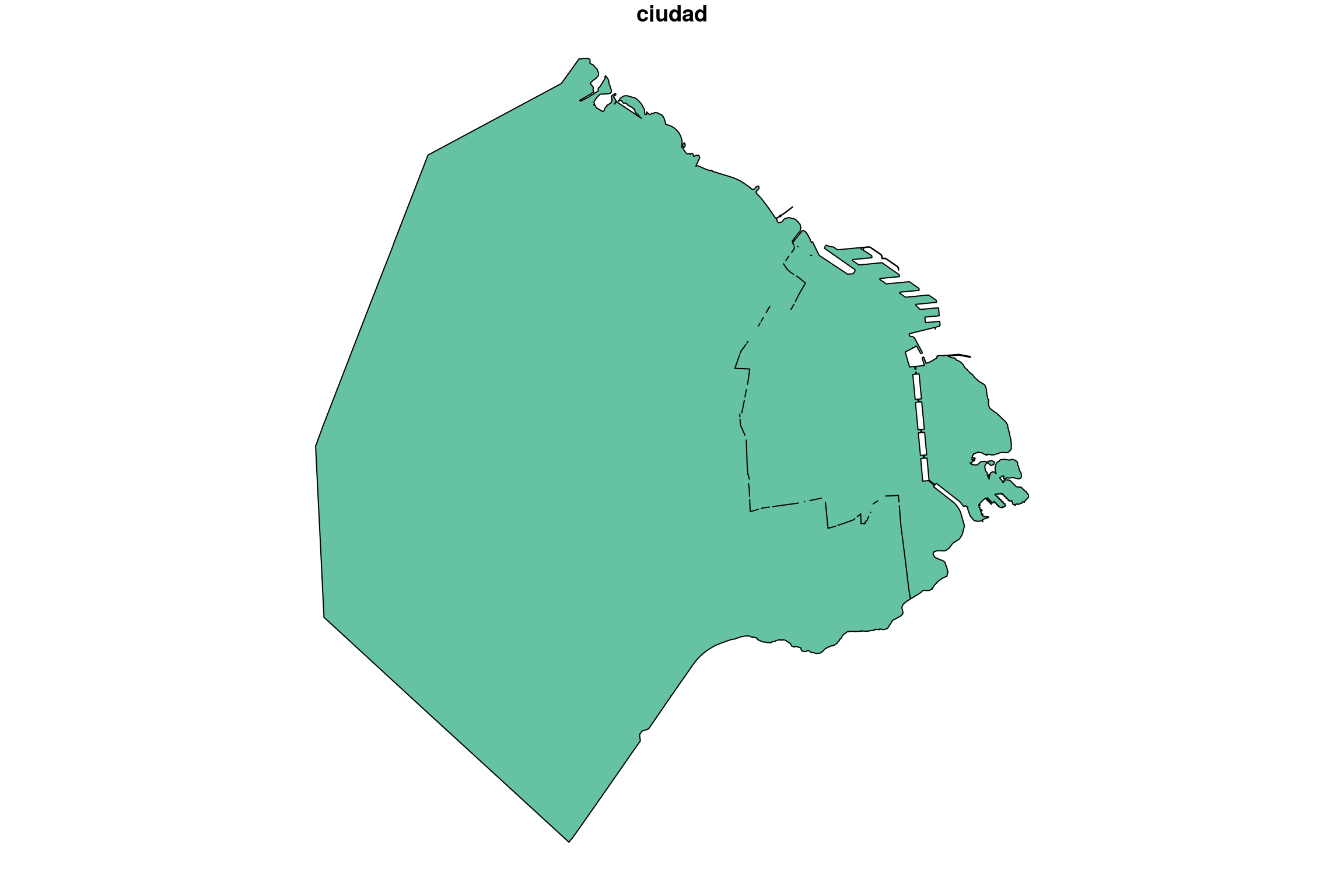
Ahora combinamos nuestra data de taxis con la silueta de la ciudad, y filtramos el resultado para descartar los puntos que cae fuera de los límites.
geo_data <- geo_data %>%
st_join(limites_CABA) %>%
filter(ciudad == "CABA")
plot(geo_data["tipo"], col = c("aquamarine", "indianred1"),
key.pos = NULL, main = "salidas en verde, llegadas en rojo")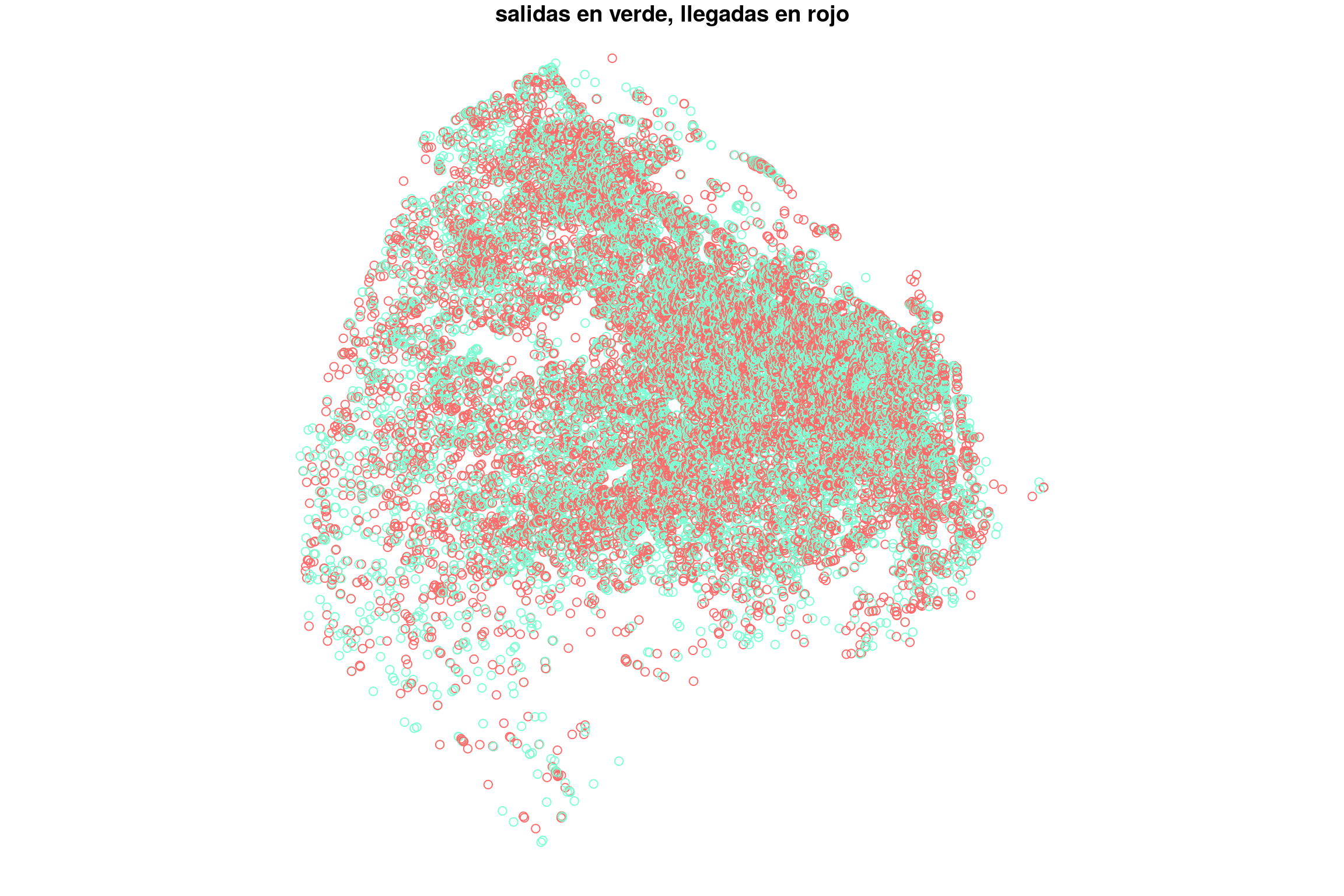 Voilà!. Ahora creamos la grilla…
Voilà!. Ahora creamos la grilla…
grilla <- geo_data %>%
st_make_grid(what = "polygons", n = c(20, 20)) %>%
st_sf() %>%
mutate(ID = row_number())
plot(geo_data["tipo"], col = c("aquamarine", "indianred1"), key.pos = NULL, main = NULL)
plot(st_geometry(grilla), add = T)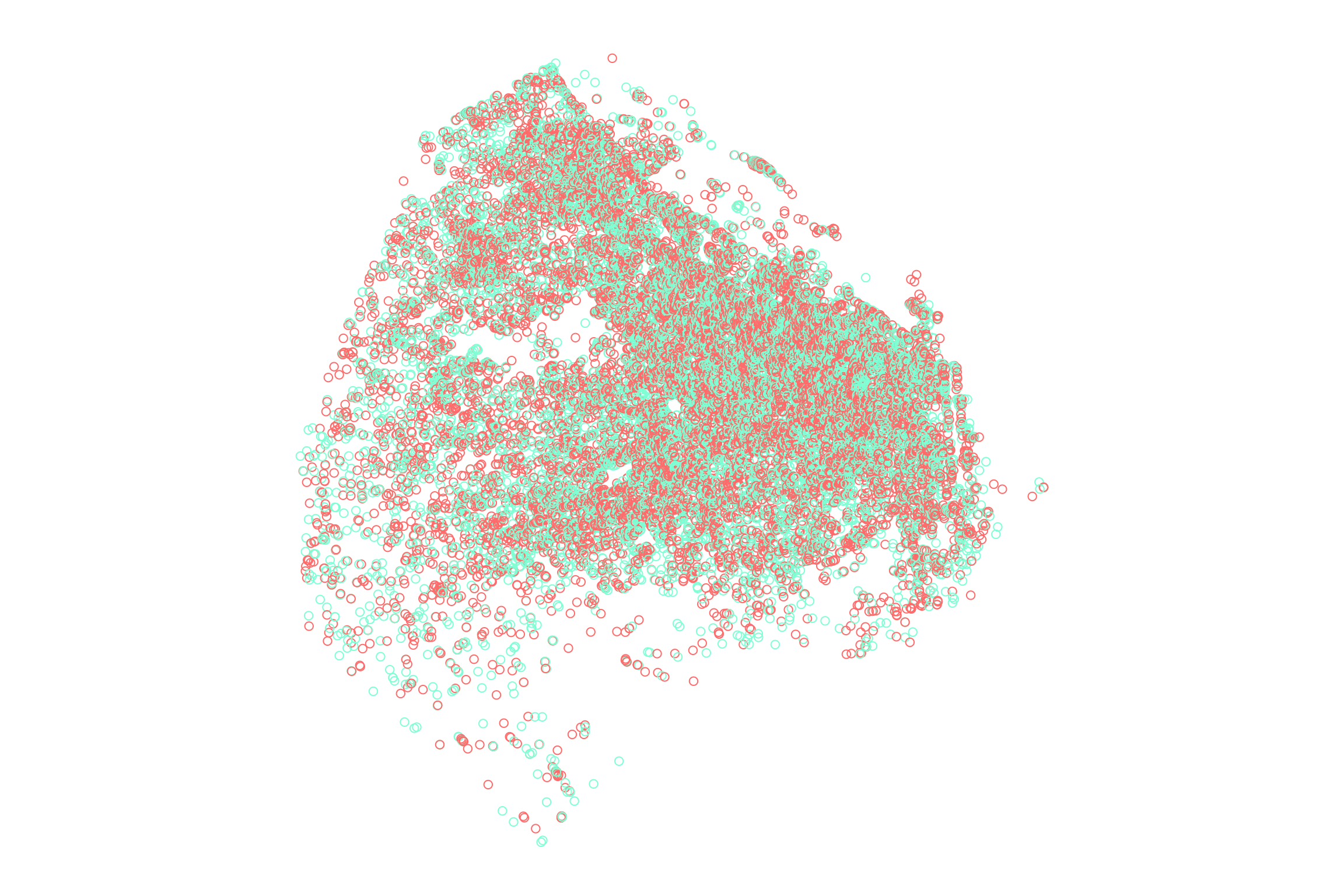
… y asociamos a cada par de coordenadas con la celda donde cae:
tasa_destino_origen <- geo_data %>%
st_join(grilla) %>%
group_by(ID) %>%
summarise(total = n(),
tasa = sum(tipo == "destino", na.rm = T) /
sum(tipo == "origen", na.rm = T))En cada celda, medimos la proporción de viajes que llegan Vs. los que se originan allí
Esto se puede hacer en una sola cadena de funciones, con un join espacial entre data de taxis y grilla, un agrupado por identificador de celda, y una cálculo a nivel celda de la relación cantidad de llegadas / cantidad de salidas
tasa_destino_origen <- geo_data %>%
st_join(grilla) %>%
group_by(ID) %>%
summarise(total = n(),
tasa = sum(tipo == "destino", na.rm = T) /
sum(tipo == "origen", na.rm = T)) %>%
# la condición "is.finite" elimina los casos donde hubo 0 salidas
filter(is.finite(tasa))Tomamos la distribución de tasas origen/destino e identificamos los casos anómalos
Antes de hacer cuentas, volvamos a anticipar los resultados con una visualización. Cómo se ve en el mapa la tasa origen/destino de cada zona de la ciudad?
plot(tasa_destino_origen["tasa"],
main = "Viajes de BA Taxi por zona: cantidad de llegadas por cada salida")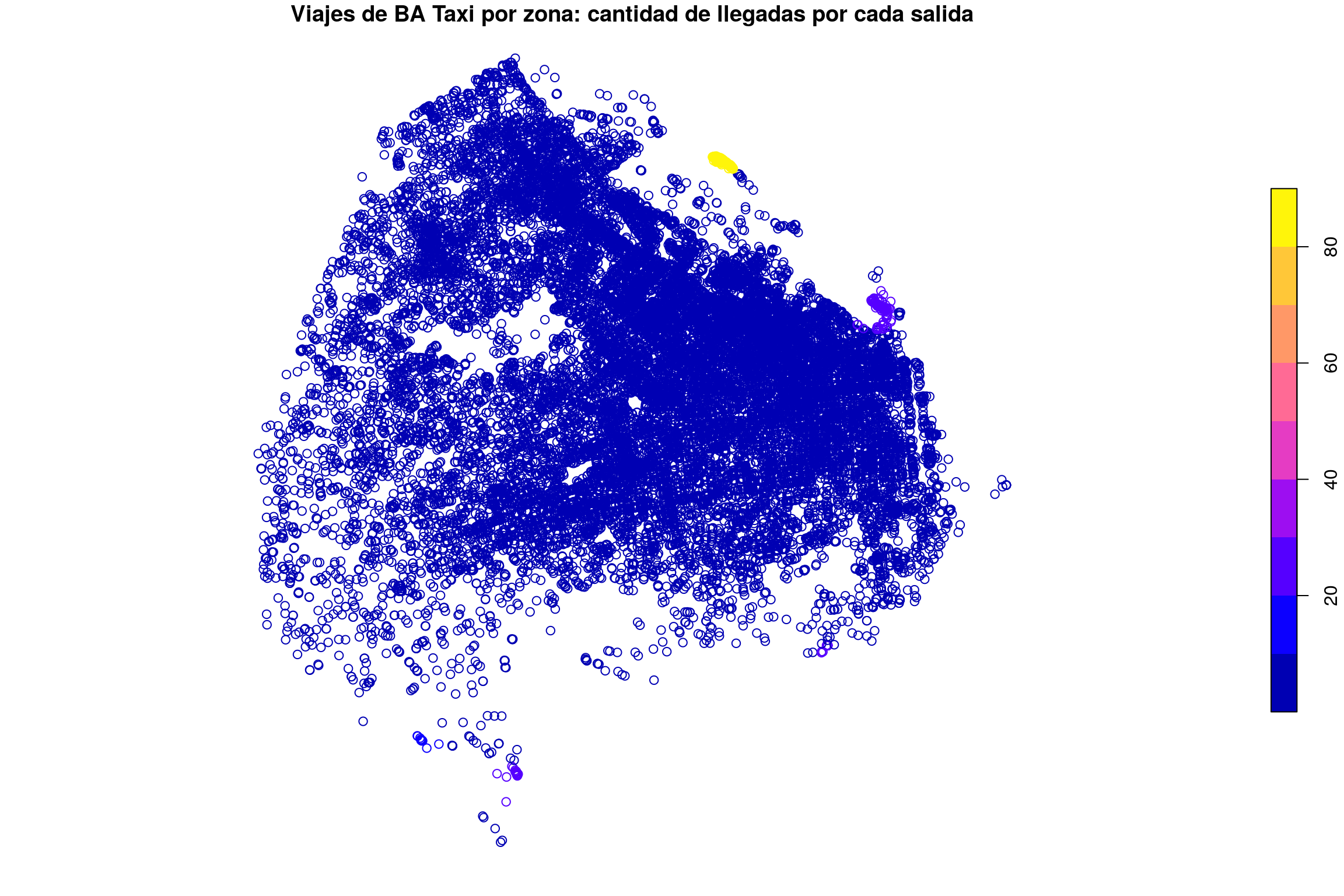
Oh si, esto salió bien. Aeroparque brilla como material radioactivo. Retiro, si bien está lejos en intensidad, también se distingue de sus alrededores.
Ahora si, los números. Filtremos la data para extraer las celdas donde la tasa es desproporcionada, eligiendo un piso (arbitrario) de 10 salidas por cada llegada.
outliers <- tasa_destino_origen %>%
arrange(desc(tasa)) %>%
filter(tasa > 10) %>%
mutate(ID = as.factor(ID))
outliers## Simple feature collection with 5 features and 3 fields
## geometry type: MULTIPOINT
## dimension: XY
## bbox: xmin: -58.49042 ymin: -34.68928 xmax: -58.37098 ymax: -34.55538
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 5 x 4
## ID total tasa geometry
## <fct> <int> <dbl> <MULTIPOINT [°]>
## 1 353 357 88.2 (-58.41605 -34.55555, -58.41598 -34.55565, -58.41597 …
## 2 27 30 29.0 (-58.47032 -34.68344, -58.46803 -34.68928, -58.46793 …
## 3 96 26 25.0 (-58.38858 -34.65836, -58.38853 -34.6581, -58.38823 -…
## 4 277 215 22.9 (-58.37959 -34.59034, -58.37943 -34.59031, -58.37802 …
## 5 45 12 11.0 (-58.49042 -34.6756, -58.49033 -34.67566, -58.48972 -…Son sólo cinco áreas, de las cuales dos registran una cantidad de viajes un orden de magnitud mayor a las demás: IDs 353 y 277, que -como podemos comprobar- corresponden en efecto a Aeroparque y Retiro:
plot(outliers["ID"])
De éste modo hemos medido el efecto de la mafia en las zonas donde operan, al menos en lo que respecta a los viajes registrados por BA Taxi. En los alrededores de Aeroparque, la tasa es de 88,25: por cada 88 taxistas que terminan un viaje allí, apenas 2 logran llevarse pasajeros. En retiro, la tasa es de casi 23 llegadas por cada salida.
Para ponerlo en perspectiva, el promedio de la ciudad es de 2,7:
mean(tasa_destino_origen$tasa)## [1] 2.732686En forma gráfica:
tasa_destino_origen %>%
mutate(media = mean(tasa)) %>%
ggplot() +
geom_histogram(aes(tasa), bins = nrow(tasa_destino_origen)) +
geom_vline(aes(xintercept = media), color = "blue") +
geom_vline(aes(xintercept = 88.25), color = "red") +
geom_vline(aes(xintercept = 22.89), color = "red") +
theme_ipsum() +
labs(title = "Relación llegadas vs. salidas de taxis",
subtitle = "Sistema BA Taxi",
x = "taxis que llegan por cada uno que sale") +
geom_label(data = data.frame(x = c(mean(tasa_destino_origen$tasa), 22.89, 88.25),
y = rep(40, 3)),
aes(x, y, label = c("Media BA", "Retiro", "Aeroparque")))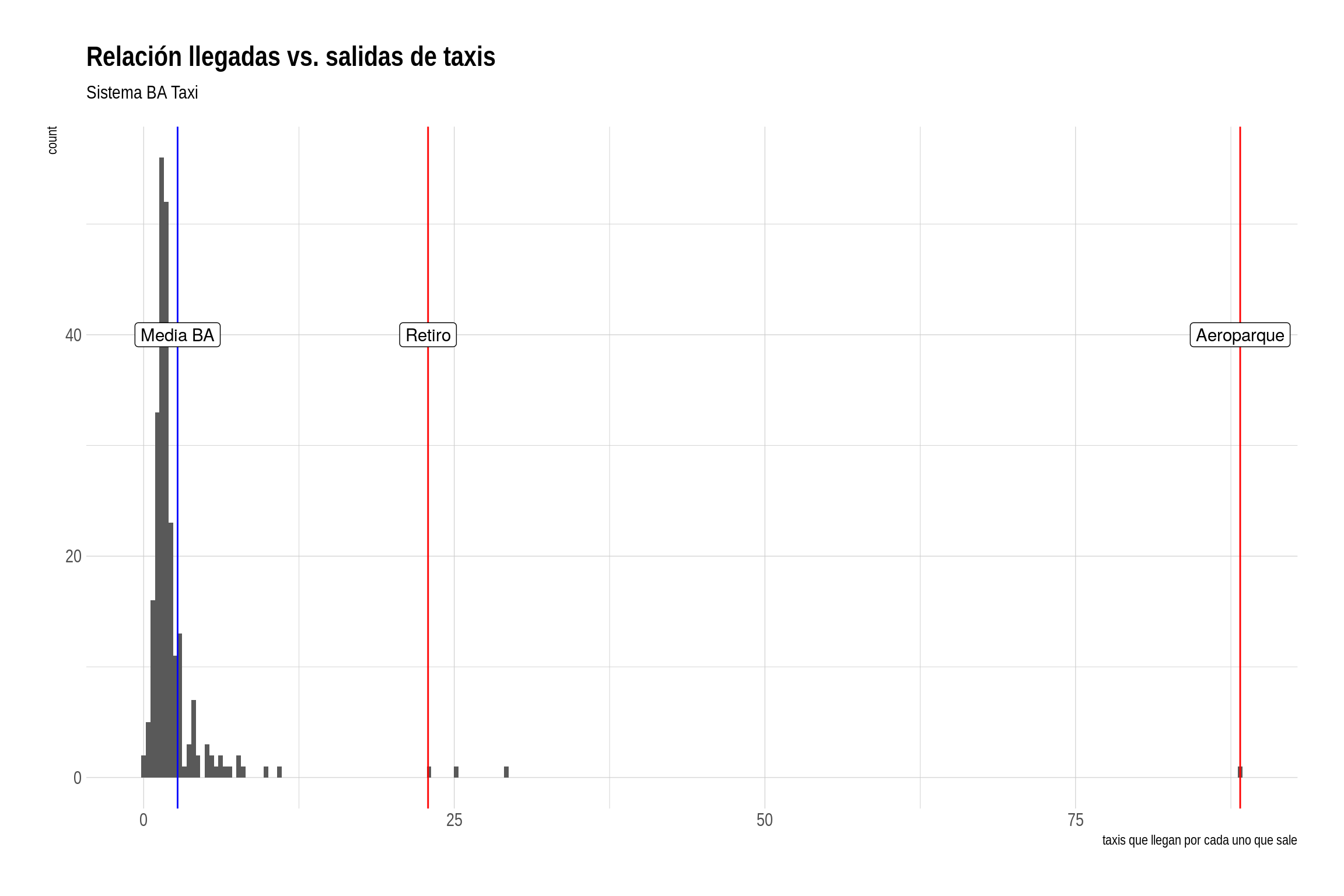
Por último: qué pasa con las otras tres zonas donde los taxis dejan pasajeros pero rara vez los van a buscar?
Se trata de un fenómeno distinto, y que amerita un análisis aparte que por ahora no vamos a desarrollar. Las otras tres zonas donde encontramos una relación desproporcionada de llegadas vs. salidas se encuentran en el sur de la Ciudad.
Es fácil superponer nuestra data sobre un mapa satelital, para jugar con el nivel de zoom e inspeccionar los alrededores:
library(mapview)
mapview(st_geometry(outliers), map.types = c("Esri.WorldImagery"))Según mi lectura, una de las celdas coincide con un área industrial. Las dos restantes con complejos habitacionales de vivienda pública.
Se me ocurre una hipótesis cuya verificación quedará pendiente: ¿Será que los choferes de BA Taxi evitan viajes con origen en éstas zonas por temor, en la práctica discriminando a esos usuarios? En ese caso, la cantidad de viajes que terminan allí se explicaría porque los taxistas inician el viaje en algún otro barrio, sin saber el destino hasta que el usuario está a bordo.
RIP Dirección Provincial de Innovación Ciudadana: http://poderciudadano.org/preocupacion-por-cambios-en-la-politica-de-gobierno-abierto-en-la-provincia-de-buenos-aires/↩