De todos los datasets que publica el portal de Open Data de Buenos Aires, mi favorito es sin dudas el que contiene los reclamos registrados por el Sistema Único de Atención Ciudadana (SUACI). El SUACI, también llamado BA 147, equivale a lo que en otras latitudes se conoce como servicio 311. El 311 es el número telefónico, complementado por un servicio web y en general una app también, al que los ciudadanos recurren para realizar reclamos al gobierno de la ciudad. En contraste con el servicio 911, el 311 (o 147 en Buenos Aires) se utiliza para reportar problemas que no involucran urgencias de salud o seguridad. Por ejemplo, si la cuadra de uno aparece llena de basura después de un evento multitudinario en las cercanías, se llama al 147 o se usa la app para que la ciudad envíe una cuadrilla de limpieza. En cambio, si una persona sufre un infarto en la vía pública, se llama al 911.
Si esto les resulta un poco confuso, no se preocupen, nos es culpa nuestra; hay un ligero exceso de nombres distintos para cosas similares. Los nombres SUACI y BA 147 coexisten porque -creo- SUACI registra las solicitudes al 147 pero también reclamos enviados a la ciudad por otros medios. En cuanto a 311 vs. 147, la popularidad de 311 como número para reclamos aún muy lejos del archifamoso 911. Por eso muchas ciudades en el mundo, BA incluida, coinciden en usar el 911 para emergencias pero varían en el número reservado para reclamos cotidianos.
Lo interesante de los servicios tipo 311 es que, cuando sus registros se comparten con el público, permiten hacer estudios sobre muchas facetas de la ciudad. Por ejemplo, identificar edificios peligrosos por su deterioro, o probar que las “fronteras” entre comunidades distintas dentro de la ciudad generan más reclamos que áreas homogéneas.
Un área que creo de particular interés es la de predecir demanda a futuro de servicios urbanos, para ayudar a planificar la asignación de los siempre limitados recursos públicos. Analizando la cantidad de reclamos que la población realiza a lo largo del tiempo, podemos detectar tendencias y pronosticar demanda futura, así como predecir los momentos y lugares de “tranquilidad” (que requieren menos recursos) así como aquellos que generan picos (donde se van a necesitar refuerzos).
A todo ésto, el área de R+I de Facebook liberó recientemente sus algoritmos de modelado y predicción para datos seriados en el tiempo, bajo el nombre de Prophet. La razón por la cual Prophet me resultó llamativo de inmediato es que hace muy fácil incorporar el efecto de días atípicos en un modelo predictivo para procesos que se desarrollan a lo largo del tiempo. En palabras de urbanista: podemos pronosticar la demanda de servicios urbanos usando registros históricos, generando un modelo que toma en cuenta el efecto de los diversos días feriados.
Allá vamos!
Obteniendo los datos de la ciudad
El primer paso es descargar los datos que necesitamos. Visitamos Buenos Aires Data, buscamos “Sistema Único de Atención Ciudadana”, y llegamos a la página de descarga que nos interesa - aquí. Tenemos disponible un link para descargar un archivo comprimido que contiene los datos que buscamos. Podemos dejar que R se encargue de acceder al sitio, descargar y descomprimir por nosotros:
# Donde vive nuestra data?
url <- "https://data.buenosaires.gob.ar/api/datasets/rJg_9jlR5/download"
# Donde queremos guardarla
destino <- '/home/havb/data/gcba/suaci'
# Creamos un archivo temporal para dscargar el zip con todos los datasets
temp <- tempfile()
# Descargamos -puede tomar unos cuantos minutos
download.file(url, temp)
# Des-zipeamos
unzip(temp, exdir = destino, junkpaths = TRUE)
# Eliminamos el archivo temporal
unlink(temp)Terminado el trámite, revisamos nuestro botín:
list.files(destino)## [1] "guia-de-datos-de-los-recursos-sistema-unico-de-atencion-ciudadana.pdf"
## [2] "sistema-unico-de-atencion-ciudadana-2011.csv"
## [3] "sistema-unico-de-atencion-ciudadana-2012.csv"
## [4] "sistema-unico-de-atencion-ciudadana-2013.csv"
## [5] "sistema-unico-de-atencion-ciudadana-2014.csv"
## [6] "sistema-unico-de-atencion-ciudadana-2015.csv"
## [7] "sistema-unico-de-atencion-ciudadana-2016.csv"
## [8] "sistema-unico-de-atencion-ciudadana.txt"He aquí el primer problema. En lugar de darnos un dataset con todo el historial de registros, nos dan una pila archivos que contienen la data separada por año. Cuando uno analiza datos a lo largo del tiempo, lo natural es tenerlos todos juntos, y luego segmentarlos -por año, por mes, o por otro período arbitrario- cuando es necesario. Y desde ya que cuando uno analiza tendencias para predecir, como estamos haciendo ahora, necesita todos los datos juntos. En fin, no es tan grave… solo es cuestión de pegar los datasets uno después del otro, no? Pues no, tenemos una sorpresa más. La estructura de los datasets cambia según el año!
Las columnas en la data del 2011 y 2012…
library(tidyverse)
names(read_delim('/home/havb/data/gcba/suaci/sistema-unico-de-atencion-ciudadana-2011.csv',
delim = ";"))## [1] "longitude" "latitude" "concepto"
## [4] "rubro" "tipo_prestacion" "fecha"
## [7] "barrio" "calle" "altura"
## [10] "esquina_proxima" "x" "y"… son distintas a las de 2013 - 2016:
names(read_delim('/home/havb/data/gcba/suaci/sistema-unico-de-atencion-ciudadana-2016.csv',
delim = ";"))## [1] "PERIODO" "CONCEPTO"
## [3] "RUBRO" "TIPO_PRESTACION"
## [5] "FECHA_INGRESO" "HORA_INGRESO"
## [7] "DOMICILIO_CGPC" "DOMICILIO_BARRIO"
## [9] "DOMICILIO_CALLE" "DOMICILIO_ALTURA"
## [11] "DOMICILIO_ESQUINA_PROXIMA" "LAT"
## [13] "LONG"la buena noticia es que el equipo de Open Data de la ciudad está arreglando este problemilla. Hace unos días hice lo que todo ciudadano responsable hace para mejorar al mundo (quejarme por internet, por supuesto)… lo notable es que recibí pronta respuesta!
Hola @vazquezbrust están separados porq son archivos q tienen + de 1 millón de registros. Gracias a tu consulta vamos a unificar los nombres
— LABgcba (@LABgcba) June 29, 2017
Desde entonces, empezaron a modificar éstos datasets en el portal de open data, unificando los nombres de los campos. Al día de hoy todavía hay discrepancias, que se resuelven con el código mostrado a continuación. Si alguien reproduce estos resultados en el futuro, es probable que todos los datasets ya hayan sido unificados en el origen, y no necesite hacer la consolidación de datos.
Por ahora, el método más sencillo para consolidar todos los archivos en un sólo dataset es concatenar los del 2011 y 2012 tomando sólo las columnas que nos interesan, y luego agregar la data de los archivos 2013 a 2016, re-ordenada para que encaje con el resto. Ah! Y el formato de la fecha en los archivos más recientes es distinta respecto a los de años anteriores, así que tendremos que acomodar eso.
Ahora, exploremos los datos unificados. Rapidito, un top ten de los reclamos más frecuentes:
suaci %>%
group_by(concepto, rubro) %>%
summarise(total = n()) %>%
arrange(desc(total)) %>%
head(10)## Source: local data frame [10 x 3]
## Groups: concepto [10]
##
## concepto
## <chr>
## 1 SOLICITUD DE PARTIDAS
## 2 SOLICITUD DE PAGO VOLUNTARIO DE INFRACCIONES
## 3 SOLICITUD DE PARTIDAS
## 4 PERSONAS SIN TECHO EVALUACION
## 5 SOLICITUD DE RETIRO DE RESTOS DE OBRAS O DEMOLICIONES DOMICILIARIAS H/ 500
## 6 RETIRO DE ESCOMBROS (RESIDUOS ARIDOS)
## 7 LUMINARIAS APAGADAS
## 8 LUMINARIA: APAGADA
## 9 PERSONAS SIN TECHO EVALUACION
## 10 SOLICITUD DE RETIRO DE RESIDUOS VOLUMINOSOS
## # ... with 2 more variables: rubro <chr>, total <int>No iba a ser tan fácil, verdad? Categorías como “SOLICITUD DE PARTIDAS” o “PERSONAS SIN TECHO EVALUACION” aparecen duplicadas. Otras, como “LUMINARIAS APAGADAS” y “LUMINARIA: APAGADA” son obvias referencias al mismo reclamo, registradas bajo categorías distintas. Vamos a arreglar el primer problema, que es fácil de resolver: Sólo hay que borrar los espacios en blanco de más al principio o final del texto. Intentemos de nuevo:
trim <- function (x) gsub("^\\s+|\\s+$", "", x)
suaci <- mutate(suaci, concepto = trim(concepto), rubro = trim(rubro))
suaci %>%
group_by(concepto, rubro) %>%
summarise(total = n()) %>%
arrange(desc(total)) %>%
head(10)## Source: local data frame [10 x 3]
## Groups: concepto [10]
##
## concepto
## <chr>
## 1 SOLICITUD DE PARTIDAS
## 2 SOLICITUD DE PAGO VOLUNTARIO DE INFRACCIONES
## 3 PERSONAS SIN TECHO EVALUACION
## 4 LUMINARIAS APAGADAS
## 5 SOLICITUD DE RETIRO DE RESIDUOS VOLUMINOSOS
## 6 SOLICITUD DE RETIRO DE RESTOS DE OBRAS O DEMOLICIONES DOMICILIARIAS H/ 500K
## 7 RETIRO DE ESCOMBROS (RESIDUOS ARIDOS)
## 8 LUMINARIA: APAGADA
## 9 VEHICULOS ABANDONADOS EN VIA PUBLICA LEY 342
## 10 SOLICITUD DE REPOSICION O CAMBIO DE UBICACION DE CONTENEDOR EN ZONA CONTENE
## # ... with 2 more variables: rubro <chr>, total <int>Ahí va mejor. Todavía sufrimos la aparición de categorías que refieren a lo mismo con distintos nombres, pero no afecta a nuestros fines. Lo que vamos a modelar son las solicitudes al departamento de saneamiento urbano: reclamos de la ciudadanía para que la ciudad retire residuos voluminosos, escombros de obra, ramas podadas, etc.
Aquí vale la pena insistir en la riqueza del dataset. Entre las categorías que aparecen con solo mirar las principales, aparecen la atención a personas sin techo, y los problemas de iluminación pública. Hay, tantas, tantas cosas que se pueden hacer mediante el análisis espacial y temporal de la data!
Aislamos los reclamos que nos interesan en este momento:
solicitudes_saneamiento <- suaci %>%
filter(grepl("RESIDUOS|RESTOS|ESCOMBROS ", concepto) == TRUE &
rubro == "SANEAMIENTO URBANO") %>%
group_by(dia = format(fecha, "%Y-%m-%d")) %>%
summarise(total = n())Y ahora los graficamos para ver que pinta tienen:
library(hrbrthemes)
ggplot(solicitudes_saneamiento, aes(as.Date(dia), total)) +
geom_line(color = "orange") +
scale_x_date(date_labels = "%Y-%m") +
theme_ipsum() +
labs(y = "solicitudes", x = "fecha",
title="Demanda diaria de servicios de saneamiento urbano",
subtitle = "Ciudad de Buenos Aires: 2011 - 2016",
caption = "Fuente: https://data.buenosaires.gob.ar/")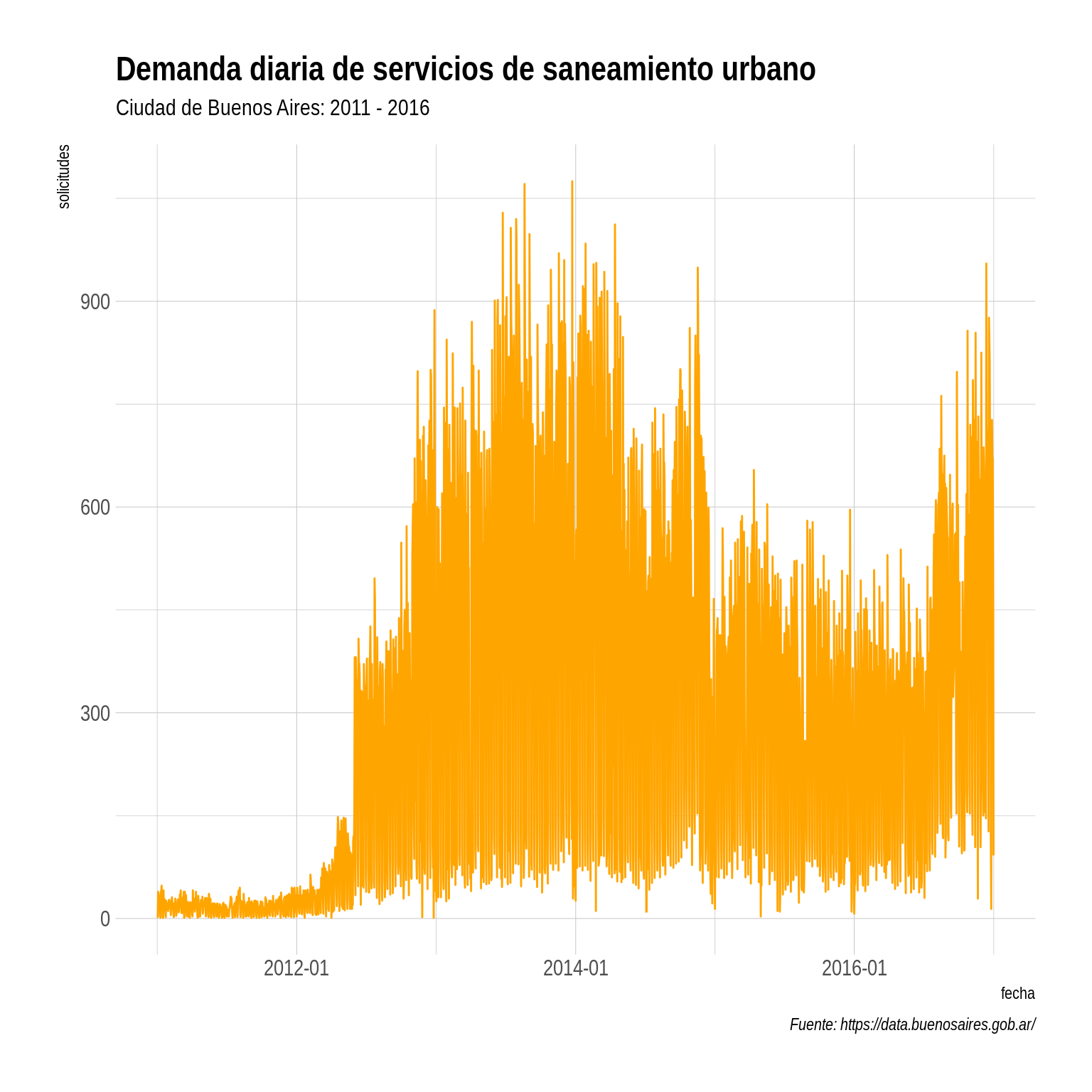
A primera vista, es obvio que los datos están sesgados, ya que la explosión en el número de solicitudes a partir de mediados del 2012 es atribuible a la forma en que la ciudad empezó a tomar nota de los reclamos, más que a un furor ciudadano por solicitar limpieza. Cuando hagamos nuestro modelo, vamos a descartar los registros de 2001 y 2012 porque tenemos claro que no son representativos.
El siguiente ingrediente que necesitamos es una lista de los feriados públicos en la Argentina durante el período analizado.
Cuando los datos están dispersos: la hora del scraping
Buscar una lista oficial de feriados resultó en frustración. Si bien el gobierno nacional publica una lista de los feriados vigentes para el año en curso, no existe un archivo para descargar con las fechas exactas de los feriados en años anteriores.
En los sitios web de varios diarios locales encontramos un historial de feriados, pero dispersos en distintas páginas web, y sin opción para descargarlos en un archivo de texto. Vamos a tener que “scrapear” la data. Cómo nos hacen laburar, che. Si tan solo alguien nos diera una API para toda información de consulta permanente, no tendríamos que hacer estas cosas!

ira
Nuestro proveedor de fechas de feriados será La Nación, que publica un bonito calendario de feriados oficiales, con la posibilidad de consultar los de años anteriores.
library(rvest)
# Una función que hace scrping de todos los feriados publicados en lanacion.com.ar para un año dado
scrape_feriados_del_anio <- function(year) {
# Donde está la data de los feriados
baseurl <- "http://servicios.lanacion.com.ar/feriados/"
get_feriados_mes <- function(month, feriados_page) {
# Los feriados aparecen en dos categorías: "inamovible" y "trasladable"
inamovibles <- feriados_page %>%
map(html_nodes, "li.inamovible") %>%
map(html_text) %>%
.[[month]] %>%
{if (!is_empty(.)) paste(year, month, ., sep = "/")}
trasladables <- feriados_page %>%
map(html_nodes, "li.trasladable") %>%
map(html_text) %>%
.[[month]] %>%
{if (!is_empty(.)) paste(year, month, ., sep = "/")}
todos <- c(inamovibles, trasladables)
if (!is.null(todos)) return(todos)
}
feriados_page <- read_html(paste0(baseurl, year)) %>%
html_nodes(".bloque")
feriados_del_anio <- map(1:12, get_feriados_mes, feriados_page) %>%
unlist()
return(feriados_del_anio)
}
# Descargamos los feriados de 2011 a 2016,
feriados_2011_2016 <- map(2013:2016, scrape_feriados_del_anio) %>%
#los unimos en un unico vector
unlist %>%
# los definimos como fecha
ymd %>%
# Los ordenamos cronológicamente (necesario porque el scraper los trae como texto
# en orden alfabetico)
sortTenemos nuestra lista de feriados?
feriados_2011_2016## [1] "2013-01-01" "2013-01-31" "2013-02-11" "2013-02-12" "2013-02-20"
## [6] "2013-03-24" "2013-03-29" "2013-04-01" "2013-04-02" "2013-05-01"
## [11] "2013-05-25" "2013-06-20" "2013-06-21" "2013-07-09" "2013-08-19"
## [16] "2013-10-14" "2013-11-25" "2013-12-08" "2013-12-25" "2014-01-01"
## [21] "2014-03-03" "2014-03-04" "2014-03-24" "2014-04-02" "2014-04-18"
## [26] "2014-05-01" "2014-05-02" "2014-05-25" "2014-06-20" "2014-07-09"
## [31] "2014-08-18" "2014-10-13" "2014-11-24" "2014-12-08" "2014-12-25"
## [36] "2014-12-26" "2015-01-01" "2015-02-16" "2015-02-17" "2015-03-23"
## [41] "2015-03-24" "2015-04-02" "2015-04-03" "2015-05-01" "2015-05-25"
## [46] "2015-06-20" "2015-07-09" "2015-08-17" "2015-10-12" "2015-11-27"
## [51] "2015-12-07" "2015-12-08" "2015-12-25" "2016-01-01" "2016-02-08"
## [56] "2016-02-09" "2016-03-24" "2016-03-25" "2016-04-02" "2016-05-01"
## [61] "2016-05-25" "2016-06-17" "2016-06-20" "2016-07-08" "2016-07-09"
## [66] "2016-08-15" "2016-10-10" "2016-11-28" "2016-12-08" "2016-12-09"
## [71] "2016-12-25"Oh si.
Modelando y prediciendo
Con todos los ingredientes a mano, es hora de hacer vaticinios. Como suele pasar cuando uno trabaja con datos, hacer el modelo es la parte más sencilla… la mayor parte del tiempo la empleamos en reunir y limpiar los datos!
Creamos un modelo:
library(prophet)
modelo <- solicitudes_saneamiento %>%
filter(year(as.Date(dia)) > 2012) %>%
transmute(ds = as.Date(dia), y = total) %>%
prophet(holidays = data.frame(holiday = "feriado", ds = feriados_2011_2016))## Initial log joint probability = -116.628
## Optimization terminated normally:
## Convergence detected: relative gradient magnitude is below toleranceY predecimos la demanda para el año siguiente (todo el 2017):
forecast <- predict(modelo, make_future_dataframe(modelo, periods = 365))De paso, hacemos dos preguntas rápidas. Cuantas solicitudes diarias recibe la ciudad, y que efecto tiene un día feriado en el nivel de demanda?
Durante el período 2012-2016, el área de saneamiento urbano de la ciudad recibió un promedio de 394 reclamos diarios, con un máximo 1075. El día en el que menos reclamos se registraron sólo hubo 3.
modelo$history$y %>% summary## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.0 121.0 392.0 394.2 603.5 1075.0Según nuestro modelo, el efecto de que un feriado caiga en un día particular del mes es una reducción de 401 reclamos. En un día típico, esto haría que prácticamente no haya reclamos.
forecast %>%
select(ds, feriado) %>%
filter(abs(feriado) > 0) %>%
head()## ds feriado
## 1 2013-01-01 -401.23
## 2 2013-01-31 -401.23
## 3 2013-02-11 -401.23
## 4 2013-02-12 -401.23
## 5 2013-02-20 -401.23
## 6 2013-03-24 -401.23Visualizando por separado la tendencias general y las periódicas (por día de la semana y día del mes) notamos varios efectos.
La tendencia general fue una baja del nivel de demanda desde el 2014 hasta el 2016, revertida luego. Se evidencia una fuerte suba de allí en más. Valdría la pena discernir si esto se debe a que la data sub-representa los reclamos del 2014-2016, o si efectivamente ocurrió una baja de demanda en esos años. Si ésto último fuera el caso, a que podría deberse?
El día de mayor actividad es el Lunes, a continuación de los días más tranquilo, los del fin de semana. Está claro que en Domingo la gente no reclama mucho, pero al día siguiente si. En el resto de los días la demanda es pareja
Tal como habíamos comprobado revisando los números, los días feriados generan una caída de unos 400 reclamos
Los meses de mayor actividad son los de la segunda mitad del año. Durante las vacaciones de invierno se observa una baja de la demanda, leve en comparación a la de fin de año…. a partir de mediados de Diciembre, la demanda cae en picada, y se mantiene mínima en Enero.
prophet_plot_components(modelo, forecast) 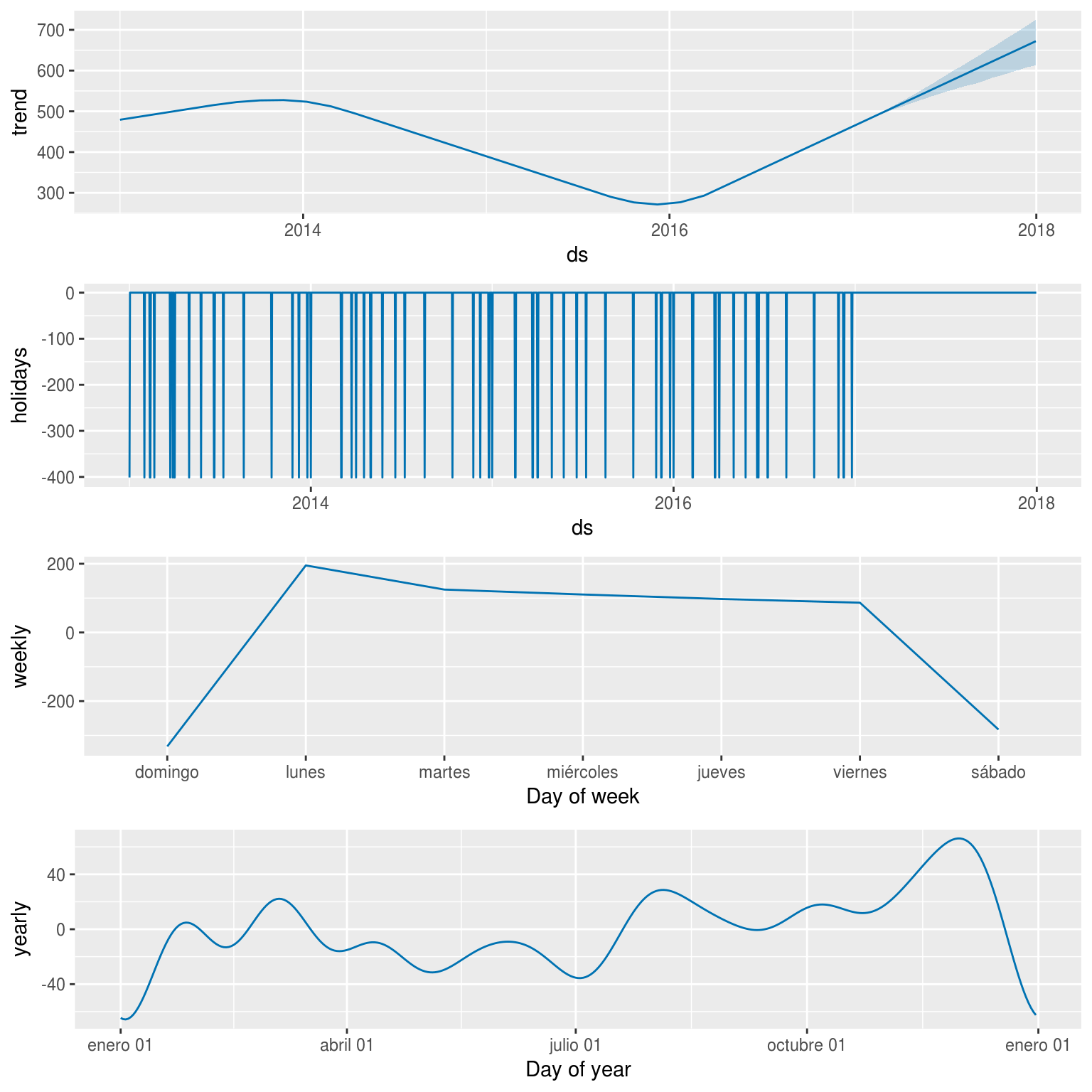
Y por último, trazamos la predicción de nivel de demanda para lo que queda del año:
plot(modelo, forecast) + theme_ipsum() +
labs(y = "solicitudes", x = "fecha",
title="Pronóstico: demanda diaria de servicios de saneamiento urbano",
subtitle = "Ciudad de Buenos Aires: 2011 - 2016, extendido a final del 2017")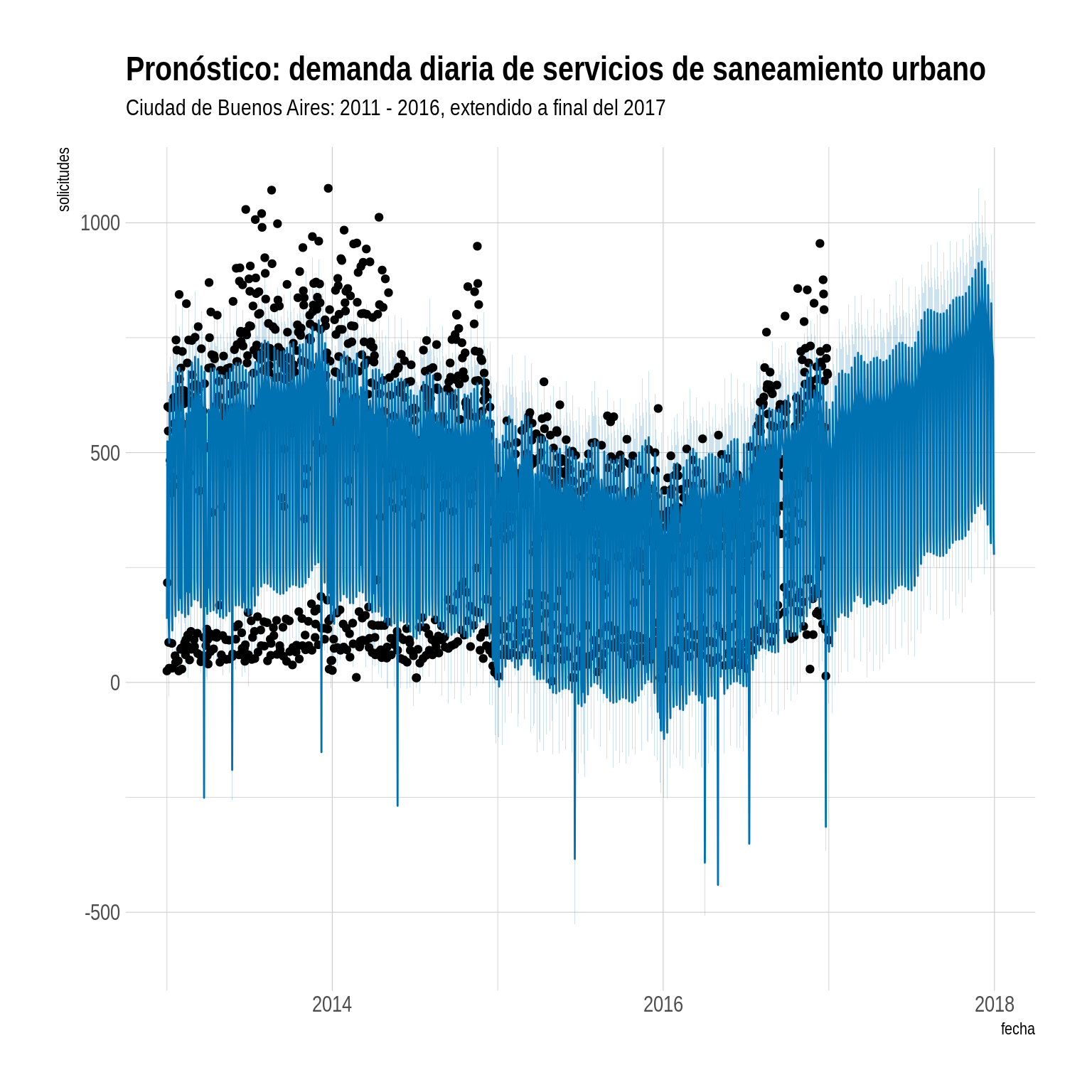
Yo diría que, a no ser que ese operando con capacidad de sobra, Saneamiento Urbano va a necesitar más recursos!
Para la próxima: hacer análisis espacial además del temporal.